-
Latest Version
Screaming Frog SEO Spider 21.4 LATEST
-
Review by
-
Operating System
Windows 7 / Windows 8 / Windows 10 / Windows 11
-
User Rating
Click to vote -
Author / Product
-
Filename
ScreamingFrogSEOSpider-21.4.exe
Download for free, or purchase a license for additional advanced features.
You might also like:
Semrush - a widely used SEO tool suite designed for keyword research, competitor analysis, and optimizing Google Ads campaigns.
The SEO Spider app is a powerful and flexible site crawler, able to crawl both small and very large websites efficiently while allowing you to analyze the results in real-time.
It gathers key onsite data to allow SEOs to make informed decisions.
What can you do with the SEO Spider Software?
Find Broken Links
Crawl a website instantly and find broken links (404s) and server errors. Bulk export the errors and source URLs to fix, or send to a developer.
Audit Redirects
Find temporary and permanent redirects, identify redirect chains and loops, or upload a list of URLs to audit in a site migration.
Analyse Page Titles & Meta Data
Analyze page titles and meta descriptions during a crawl and identify those that are too long, short, missing, or duplicated across your site.
Discover Duplicate Content
Discover exact duplicate URLs with an md5 algorithmic check, partially duplicated elements such as page titles, descriptions, or headings, and find low content pages.
Extract Data with XPath
Collect any data from the HTML of a web page using CSS Path, XPath, or regex. This might include social meta tags, additional headings, prices, SKUs, or more!
Review Robots & Directives
View URLs blocked by robots.txt, meta robots, or X-Robots-Tag directives such as ‘noindex’ or ‘nofollow’, as well as canonicals and rel=“next” and rel=“prev”.
Generate XML Sitemaps
With Screaming Frog you can quickly create XML Sitemaps and Image XML Sitemaps, with advanced configuration over URLs to include last modified, priority, and change frequency.
Integrate with Google Analytics
Connect to the Google Analytics API and fetch user data, such as sessions or bounce rate and conversions, goals, transactions, and revenue for landing pages against the crawl.
Crawl JavaScript Websites
Render web pages using the integrated Chromium WRS to crawl dynamic, JavaScript rich websites and frameworks, such as Angular, React, and Vue.js.
Visualise Site Architecture
Evaluate internal linking and URL structure using interactive crawl and directory force-directed diagrams and tree graph site visualizations.
Features and Highlights
- Find Broken Links, Errors & Redirects
- Analyse Page Titles & Meta Data
- Review Meta Robots & Directives
- Audit hreflang Attributes
- Discover Duplicate Pages
- Generate XML Sitemaps
- Site Visualisations
- Crawl Limit
- Scheduling
- Crawl Configuration
- Save Crawls & Re-Upload
- Custom Source Code Search
- Custom Extraction
- Google Analytics Integration
- Search Console Integration
- Link Metrics Integration
- Rendering (JavaScript)
- Custom robots.txt
- AMP Crawling & Validation
- Structured Data & Validation
- Store & View Raw & Rendered HTML
A quick summary of some of the data collected in a crawl include:
- Errors – Client errors such as broken links & server errors (No responses, 4XX, 5XX).
- Redirects – Permanent, temporary redirects (3XX responses) & JS redirects.
- Blocked URLs – View & audit URLs disallowed by the robots.txt protocol.
- Blocked Resources – View & audit blocked resources in rendering mode.
- External Links – All external links and their status codes.
- Protocol – Whether the URLs are secure (HTTPS) or insecure (HTTP).
- URI Issues – Non-ASCII characters, underscores, uppercase characters, parameters, or long URLs.
- Duplicate Pages – Hash value / MD5checksums algorithmic check for exact duplicate pages.
- Page Titles – Missing, duplicate, over 65 characters, short, pixel width truncation, same as h1, or multiple.
- Meta Description – Missing, duplicate, over 156 characters, short, pixel width truncation or multiple.
- Meta Keywords – Mainly for reference, as they are not used by Google, Bing, or Yahoo.
- File Size – Size of URLs & images.
- Response Time.
- Last-Modified Header.
- Page (Crawl) Depth.
- Word Count.
- H1 – Missing, duplicate, over 70 characters, multiple.
- H2 – Missing, duplicate, over 70 characters, multiple.
- Meta Robots – Index, noindex, follow, nofollow, noarchive, nosnippet, noodp, noydir, etc.
- Meta Refresh – Including target page and time delay.
- Canonical link element & canonical HTTP headers.
- X-Robots-Tag.
- Pagination – rel=“next” and rel=“prev”.
- Follow & Nofollow – At page and link level (true/false).
- Redirect Chains – Discover redirect chains and loops.
- hreflang Attributes – Audit missing confirmation links, inconsistent & incorrect language codes, noncanonical hreflang, and more.
- AJAX – Select to obey Google’s now deprecated AJAX Crawling Scheme.
- Rendering – Crawl JavaScript frameworks like AngularJS and React, by crawling the rendered HTML after JavaScript has executed.
- Inlinks – All pages linking to a URI.
- Outlinks – All pages a URI links out to.
- Anchor Text – All link text. Alt text from images with links.
- Images – All URIs with the image link & all images from a given page. Images over 100kb, missing alt text, alt text over 100 characters.
- User-Agent Switcher – Crawl as Googlebot, Bingbot, Yahoo! Slurp, mobile user-agents, or your own custom UA.
- Custom HTTP Headers – Supply any header value in a request, from Accept-Language to cookie.
- Custom Source Code Search – Find anything you want in the source code of a website! Whether that’s Google Analytics code, specific text, or code, etc.
- Custom Extraction – Scrape any data from the HTML of a URL using XPath, CSS Path selectors, or regex.
- Google Analytics Integration – Connect to the Google Analytics API and pull in user and conversion data directly during a crawl.
- Google Search Console Integration – Connect to the Google Search Analytics API and collect impression, click, and average position data against URLs.
- External Link Metrics – Pull external link metrics from Majestic, Ahrefs, and Moz APIs into a crawl to perform content audits or profile links.
- XML Sitemap Generation – Create an XML sitemap and an image sitemap using the SEO spider.
- Custom robots.txt – Download, edit and test a site’s robots.txt using the new custom robots.txt.
- Rendered Screen Shots – Fetch, view, and analyze the rendered pages crawled.
- Store & View HTML & Rendered HTML – Essential for analysing the DOM.
- AMP Crawling & Validation – Crawl AMP URLs and validate them, using the official integrated AMP Validator.
- XML Sitemap Analysis – Crawl an XML Sitemap independently or part of a crawl, to find missing, non-indexable, and orphan pages.
- Visualizations – Analyse the internal linking and URL structure of the website, using the crawl and directory tree force-directed diagrams and tree graphs.
- Structured Data & Validation – Extract & validate structured data against Schema.org specifications and Google search features.
- Install the software on your Windows PC
- Launch the application after installation
- Enter your website URL in the search bar
- Click "Start" to begin the website crawl
- Wait for the crawl to complete
- Review crawl data across multiple tabs
- Use filters to analyze specific SEO issues
- Export data for reporting or further analysis
- Adjust crawl settings for custom requirements
- Detect broken links, errors, and redirects – ✅ Both versions
- Analyze titles & meta data – ✅ Both versions
- Review meta robots & directives – ✅ Both versions
- Audit hreflang attributes – ✅ Both versions
- Identify exact duplicate pages – ✅ Both versions
- Generate XML sitemaps – ✅ Both versions
- Visual site crawl maps – ✅ Both versions
- Crawl limit – Free: 500 URLs | ✅ Paid: Unlimited
- Schedule crawls – ❌ Free | ✅ Paid
- Advanced crawl configuration – ❌ Free | ✅ Paid
- Save and open crawls – ❌ Free | ✅ Paid
- Render JavaScript – ❌ Free | ✅ Paid
- Compare different crawls – ❌ Free | ✅ Paid
- Detect near duplicate content – ❌ Free | ✅ Paid
- Use custom robots.txt – ❌ Free | ✅ Paid
- Test mobile usability – ❌ Free | ✅ Paid
- Crawl and validate AMP – ❌ Free | ✅ Paid
- Validate structured data – ❌ Free | ✅ Paid
- Run spelling & grammar checks – ❌ Free | ✅ Paid
- Search source code – ❌ Free | ✅ Paid
- Extract custom data – ❌ Free | ✅ Paid
- Add custom JavaScript – ❌ Free | ✅ Paid
- Use OpenAI & Gemini – ❌ Free | ✅ Paid
- Integrate Google Analytics – ❌ Free | ✅ Paid
- Connect to Search Console – ❌ Free | ✅ Paid
- Integrate PageSpeed Insights – ❌ Free | ✅ Paid
- Audit accessibility – ❌ Free | ✅ Paid
- Link metrics integration – ❌ Free | ✅ Paid
- Forms-based authentication – ❌ Free | ✅ Paid
- Segment crawl data – ❌ Free | ✅ Paid
- Export Looker Studio reports – ❌ Free | ✅ Paid
- Technical support – ❌ Free | ✅ Paid
Free version – €0/year
Paid version – €239/year
System Requirements
- Windows 7, 8, 10, or 11 (64-bit)
- At least 2 GB RAM (8 GB or more recommended)
- At least 500 MB of available disk space
- Java 11 or higher (included with installer)
- Stable internet connection for updates and support
- Fast and detailed SEO crawling
- Customizable crawl configurations
- Exports to Excel, CSV, and Google Sheets
- Finds broken links and redirects
- Integrates with Google Analytics
- Steep learning curve for beginners
- Free version has crawl limits
- High memory use on large sites
- Interface can feel cluttered
- No built-in keyword tracking
Also Available: Download Screaming Frog for Mac
-
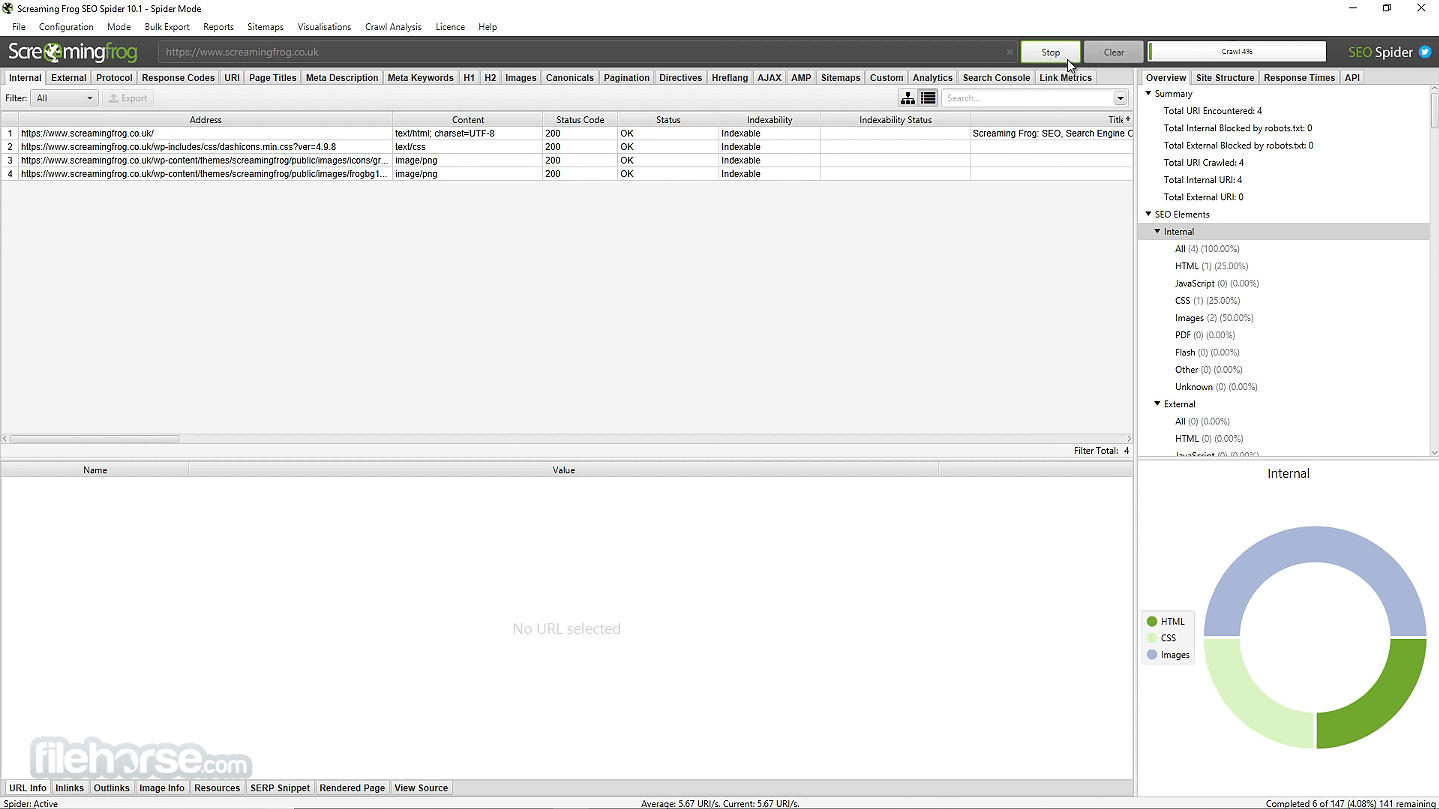
Screaming Frog SEO Spider 21.4 Screenshots
The images below have been resized. Click on them to view the screenshots in full size.
-

-

-

-

What's new in this version:
Screaming Frog 21.4
- Updated parsing of some relative URL types to correct behaviour
Fixed:
- issue in rendered crawls that would use more memory
- issue failing to collect image dimensions in some HTML
- issue with scheduled crawls in list mode not appearing in scheduled crawl history
- issue with PSI not auto connecting when set to ‘Local’
- various issues with tiling window managers in Linux (i3 and Sway)
- various unique crashes
Screaming Frog 21.3
- Update AMP validation to latest version
Fixed:
- issue with invalid schedules being created when removing email from notifications
- issue with GA4/GSC crawls sometimes not completing
- issue with loading in some AI API presets
- various unique crashes
Screaming Frog 21.2
- Reduce AI credit use by not sending blank prompts
- Ensure all images in JavaScript rendering mode are available to AI APIs
Fixed:
- issue with browser not finding accessibility issues when opened
- issue preventing crawls being exported via the right click option in the crawls dialog
- a bug with segments ‘greater than’ operator not working correctly
- various unique crashes
Screaming Frog 21.1
- Bug fixes
Screaming Frog 21.0
- Direct AI API Integration (OpenAI, Gemini & Ollama), Accessibility, Email Notifications and Custom Search Bulk Upload
Screaming Frog 20.4
- Bug fixes
Screaming Frog 20.3
- Bug fixes
Screaming Frog 20.2
- Bug fixes
Screaming Frog 20.1
- Bug fixes
Screaming Frog 20.0
- Custom JavaScript Snippets, Mobile Usability, N-grams Analysis, Aggregated Anchor Text, Local Lighthouse Integration, Carbon Footprint & Rating
Screaming Frog 19.8
Fixed:
- issue not being able to pause a crawl when API data is loaded post crawl
- issue with double hyphen not working in some URLs
- crash entering file:// prefixed URLs in Visual Custom Extraction, this is no longer allowed
- crash when dealing wtih really large robots.txt files
Screaming Frog 19.7
Fixed:
- issue not being able to pause a crawl when API data is loaded post crawl
- issue with double hyphen not working in some URLs
- crash entering file:// prefixed URLs in Visual Custom Extraction, this is no longer allowed
- crash on macOS when the app looses focus
- crash when dealing wtih really large robots.txt files
Screaming Frog 19.6
- Bug fixes
Screaming Frog 19.5
- Bug fixes
Screaming Frog 19.4
Fixed:
- an issue with JavaScript rendering and redirects
- an issue causing a crash when seleting the bounce rate metric in GA4
Screaming Frog 19.3
- Added Subscription, Paywalled Content and Vehicle Listing rich result features to structured data validation
- Removed Google How-To feature
- Updated to Schema.org version 23
- Bring Sitemap only user-agent directive handling in line with Googlebot’s updated behaviour
- Introduced synced scrolling of duplicate content frames in the Duplicate Details Tab
- Updated ‘View > Reset Columns for All Tables’ to also reset visibility if disabled
- Added right-hand Segments Tab & Overview filter to ‘Reports’ to allow exporting in Scheduling / CLI
- Added indication as to why ‘OK’ button is disabled when there is an error on another tab in system config
Fixed:
- issue with page transfer size missing in rendered crawls
- issue with image in ‘Missing Alt Attribute’ filter during JavaScript rendering
- issue with PageSpeed tab not appearing if you enable PSI mid-crawl with focus mode enabled
- issue with Microdata not parsing
- issue with unreadable scheduled crawl history errors
- issue where Forms Auth was not using the user-agent from the working config
- issue with various sites not loading in forms based authentication
- various disaply issues with the config windows
- various crashes
- Update Chrome to resolve WebP exploit CVE-2023-4863
Screaming Frog 19.2
- Bug fixes
Screaming Frog 19.1
- Bug fixes
Screaming Frog 19.0
- Updated Design, Unified Config, Segments, Visual Custom Extraction, 3D Visualisations, New Filters & Issues
Screaming Frog 18.5
- Bug fixes
Screaming Frog 18.4
- Bug fixes
Screaming Frog 18.3
- Bug fixes
Screaming Frog 18.2
- Bug fixes
Screaming Frog 18.1
- Bug fixes
Screaming Frog 18.0
GA4 Integration:
- It’s taken a little while, but like most SEOs, we’ve finally come to terms that we’ll have to actually switch to GA4. You’re now able to (begrudgingly) connect to GA4 and pull in analytics data in a crawl via their new API.
- Connect via ‘Config > API Access > GA4’, select from 65 available metrics, and adjust the date and dimensions.
- Similar to the existing UA integration, data will quickly appear under the ‘Analytics’ and Internal tabs when you start crawling in real-time
- You can apply ‘filter’ dimensions like in the GA UI, including first user, or session channel grouping with dimension values, such as ‘organic search’ to refine to a specific channel
- If there are any other dimensions or filters you’d like to see supported, then do let us know
Parse PDFs:
- PDFs are not the sexiest thing in the world, but due to the number of corporates and educational institutions that have requested this over the years, we felt compelled to provide support parsing them. The SEO Spider will now crawl PDFs, discover links within them and show the document title as the page title.
- This means users can check to see whether links within PDFs are functioning as expected and issues like broken links will be reported in the usual way in the Response Codes tab. The outlinks tab will be populated, and include details such as response codes, anchor text and even what page of the PDF a link is on.
- You can also choose to ‘Extract PDF Properties’ and ‘Store PDF’ under ‘Config > Spider > Extraction’ and the PDF subject, author, created and modified dates, page count and word count will be stored.
- PDFs can be bulk saved and exported via ‘Bulk Export > Web > All PDF Documents’.
- If you’re interested in how search engines crawl and index PDFs, check out a couple of tweets where we shared some insights from internal experiments for both Google and Bing.
Validation Tab:
- There’s a new Validation tab, which performs some basic best practice validations that can impact crawlers when crawling and indexing. This isn’t W3C HTML validation which is a little too strict, the aim of this tab is to identify issues that can impact search bots from being able to parse and understand a page reliably.
- Most SEOs know about invalid HTML elements in the head causing it to close early, but there are other interesting fix-ups and quirks that both browsers like Chrome (and subsequently) Google do if it sees a non-head element prior to the head in the HTML (it creates its own blank head), or if there are multiple, or missing HTML elements etc.
- The new filters include –
- Invalid HTML Elements In – Pages with invalid HTML elements within the . When an invalid element is used in the , Google assumes the end of the element and ignores any elements that appear after the invalid element. This means critical elements that appear after the invalid element will not be seen. The element as per the HTML standard is reserved for title, meta, link, script, style, base, noscript and template elements only.
- Not First In Element – Pages with an HTML element that proceed the element in the HTML. The should be the first element in the element. Browsers and Googlebot will automatically generate a element if it’s not first in the HTML. While ideally elements would be in the, if a valid element is first in the it will be considered as part of the generated. However, if nonelements such as ,, etc are used before the intended element and its metadata, then Google assumes the end of the element. This means the intendedelement and its metadata may only be seen in theand ignored.
- Missing Tag – Pages missing a element within the HTML. The element is a container for metadata about the page, that’s placed between theandtag. Metadata is used to define the page title, character set, styles, scripts, viewport and other data that are critical to the page. Browsers and Googlebot will automatically generate a element if it’s omitted in the markup, however it may not contain meaningful metadata for the page and this should not be relied upon.
- Multiple Tags – Pages with multiple elements in the HTML. There should only be one element in the HTML which contains all critical metadata for the document. Browsers and Googlebot will combine metadata from subsequentelements if they are both before the, however, this should not be relied upon and is open to potential mix-ups. Anytags after thestarts will be ignored.
- MissingTag – Pages missing aelement within the HTML. Theelement contains all the content of a page, including links, headings, paragraphs, images and more. There should be oneelement in the HTML of the page. Browsers and Googlebot will automatically generate aelement if it’s omitted in the markup, however, this should not be relied upon.
- MultipleTags – Pages with multipleelements in the HTML. There should only be oneelement in the HTML which contains all content for the document. Browsers and Googlebot will try to combine content from subsequentelements, however, this should not be relied upon and is open to potential mix-ups.
- HTML Document Over 15MB – Pages which are over 15MB in document size. This is important as Googlebot limit their crawling and indexing to the first 15MB of an HTML file or supported text-based file. This size does not include resources referenced in the HTML such as images, videos, CSS, and JavaScript that are fetched separately. Google only considers the first 15MB of the file for indexing and stops crawling afterwards. The file size limit is applied on the uncompressed data. The median size of an HTML file is about 30 kilobytes (KB), so pages are highly unlikely to reach this limit.
- We plan on extending our validation checks and filters over time.
In-App Updates:
- Every time we release an update there will always be one or two users that remind us that they have to painstakingly visit our website, and click a button to download and install the new version.
- WHY do we have to put them through this torture?
- The simple answer is that historically we’ve thought it wasn’t a big deal and it’s a bit of a boring enhancement to prioritise over so many other super cool features we could build. With that said, we do listen to our users, so we went ahead and prioritised the boring-but-useful feature.
- You will now be alerted in-app when there’s a new version available, which will have already silently downloaded in the background. You can then install in a few clicks.
- We’re planning on switching our installer, so the number of clicks required to install and auto-restart will be implemented soon, too. We can barely contain our excitement
Authentication for Scheduling / CLI:
- Previously, the only way to authenticate via scheduling or the CLI was to supply an ‘Authorization’ HTTP header with a username and password via the HTTP header config, which worked for standards based authentication – rather than web forms
- We’ve now made this much simpler, and not just for basic or digest authentication, but web form authentication as well. In ‘Config > Authentication’, you can now provide the username and password for any standards based authentication, which will be remembered so you only need to provide it once.
- You can also login as usual via ‘Forms Based’ authentication and the cookies will be stored
- When you have provided the relevant details or logged in, you can visit the new ‘Profiles’ tab, and export a new .seospiderauthconfig file
- This file which has saved authentication for both standards and forms based authentication can then be supplied in scheduling, or the CLI
- This means for scheduled or automated crawls the SEO Spider can login to not just standards based authentication, but web forms where feasible as well
New Filters & Issues:
- There’s a variety of new filters and issues available across existing tabs that help better filter data, or communicate issues discovered
- Many of these were already available either via another filter, or from an existing report like ‘Redirect Chains’. However, they now have their own dedicated filter and issue in the UI, to help raise awareness. These include –
- ‘Response Codes > Redirect Chains’ – Internal URLs that redirect to another URL, which also then redirects. This can occur multiple times in a row, each redirect is referred to as a ‘hop’. Full redirect chains can be viewed and exported via ‘Reports > Redirects > Redirect Chains’.
- ‘Response Codes > Redirect Loop’ – Internal URLs that redirect to another URL, which also then redirects. This can occur multiple times in a row, each redirect is referred to as a ‘hop’. This filter will only populate if a URL redirects to a previous URL within the redirect chain. Redirect chains with a loop can be viewed and exported via ‘Reports > Redirects > Redirect Chains’ with the ‘Loop’ column filtered to ‘True’.
- ‘Images > Background Images’ – CSS background and dynamically loaded images discovered across the website, which should be used for non-critical and decorative purposes. Background images are not typically indexed by Google and browsers do not provide alt attributes or text on background images to assistive technology.
- ‘Canonicals > Multiple Conflicting’ – Pages with multiple canonicals set for a URL that have different URLs specified (via either multiple link elements, HTTP header, or both combined). This can lead to unpredictability, as there should only be a single canonical URL set by a single implementation (link element, or HTTP header) for a page.
- ‘Canonicals > Canonical Is Relative’ – Pages that have a relative rather than absolute rel=”canonical” link tag. While the tag, like many HTML tags, accepts both relative and absolute URLs, it’s easy to make subtle mistakes with relative paths that could cause indexing-related issues.
- ‘Canonicals > Unlinked’ – URLs that are only discoverable via rel=”canonical” and are not linked-to via hyperlinks on the website. This might be a sign of a problem with internal linking, or the URLs contained in the canonical.
- ‘Links > Non-Indexable Page Inlinks Only’ – Indexable pages that are only linked-to from pages that are non-indexable, which includes noindex, canonicalised or robots.txt disallowed pages. Pages with noindex and links from them will initially be crawled, but noindex pages will be removed from the index and be crawled less over time. Links from these pages may also be crawled less and it has been debated by Googlers whether links will continue to be counted at all. Links from canonicalised pages can be crawled initially, but PageRank may not flow as expected if indexing and link signals are passed to another page as indicated in the canonical. This may impact discovery and ranking. Robots.txt pages can’t be crawled, so links from these pages will not be seen.
Flesch Readability Scores:
- Flesch readability scores are now calculated and included within the ‘Content‘ tab with new filters for ‘Readability Difficult’ and Readability Very Difficult’.
- Please note, the readability scores are suited for English language, and we may provide support to additional languages or alternative readability scores for other languages in the future.
- Readability scores can be disabled under ‘Config > Spider > Extraction’
Other Updates:
Auto Complete URL Bar:
- The URL bar will now show suggested URLs to enter as you type based upon previous URL bar history, which a user can quickly select to help save precious seconds.
- Response Code Colours for Visualisations:
- You’re now able to select to ‘Use Response Code Node Colours’ in crawl visualisations.
- This means nodes for no responses, 2XX, 3XX, 4XX and 5XX buckets will be coloured individually, to help users spot issues related to responses more effectively.
XML Sitemap Source In Scheduling:
- You can now choose an XML Sitemap URL as the source in scheduling and via the CL in list mode like the regular UI
Screaming Frog 17.2
- Bug fixes
Screaming Frog 17.1
- Bug fixes
Screaming Frog 17.0
- Issues Tab, Links Tab, New Limits, ‘Multiple Properties’ Config For URL Inspection API, Apple Silicon Version & RPM for Fedora and Detachable Tabs
Screaming Frog 16.7
This release is mainly bug fixes and small improvements:
- URL inspection can now be resumed from a saved crawl
- The automated Screaming Frog Data Studio Crawl Report now has a URL Inspection page
- Added ‘Days Since Last Crawl’ column for the URL Inspection integration
- Added URL Inspection data to the lower ‘URL Details’ tab
- Translations are now available for the URL Inspection integration
- Fixed a bug moving tabs and filters related to URL Inspection in scheduling
- Renamed two ‘Search Console’ filters – ‘No Search Console Data’ to ‘No Search Analytics Data’ and ‘Non-Indexable with Search Console Data’ to ‘Non-Indexable with Search Analytics Data’ to be more specific regarding the API used
- Fix crash loading scheduled tasks
- Fix crash removing URLs
Screaming Frog 16.6
- Change log not available for this version
Screaming Frog 16.5
- Update to Apache log4j 2.17.0 to fix CVE-2021-45046 and CVE-2021-45105
- Show more detailed crawl analysis progress in the bottom status bar when active
- Fix JavaScript rendering issues with POST data
- Improve Google Sheets exporting when Google responds with 403s and 502s
- Be more tolerant of leading/trailing spaces for all tab and filter names when using the CLI
- Add auto naming for GSC accounts, to avoid tasks clashing
- Fix crash running link score on crawls with URLs that have a status of “Rendering Failed”
Screaming Frog 16.4
- Bug fixes
Screaming Frog 16.3
This release is mainly bug fixes and small improvements:
- The Google Search Console integration now has new filters for search type (Discover, Google News, Web etc) and supports regex as per the recent Search Analytics API update
- Fix issue with Shopify and CloudFront sites loading in Forms Based authentication browser
- Fix issue with cookies not being displayed in some cases
- Give unique names to Google Rich Features and Google Rich Features Summary report file names
- Set timestamp on URLs loaded as part of JavaScript rendering
- Fix crash running on macOS Monetery
- Fix right click focus in visualisations
- Fix crash in Spelling and Grammar UI
- Fix crash when exporting invalid custom extraction tabs on the CLI
- Fix crash when flattening shadow DOM
- Fix crash generating a crawl diff
- Fix crash when the Chromium can’t be initialised
Screaming Frog 16.2
Fixed:
- issue with corrupt fonts for some users
- bug in the UI that allowed you to schedule a crawl without a crawl seed in Spider Mode
- stall opening saved crawls
- issues with upgrades of database crawls using excessive disk space
- issue with exported HTML visualisations missing pop up help
- issue with PSI going too fast
- issue with Chromium requesting webcam access
- crash when cancelling an export
- crash during JavaScript crawling
- crash accessing visualisations configuration using languages other then English
Screaming Frog 16.1
Updated:
- some Spanish translations based on feedback
- SERP Snippet preview to be more in sync with current SERPs
Fixed:
- preventing the Custom Crawl Overview report for Data Studio working in languages other than English
- resuming crawls with saved Internal URL configuration
- caused by highlighting a selection then clicking another cell in both list and tree views
- duplicating a scheduled crawl
- during JavaScript crawl
Screaming Frog 16.0
- Improved JavaScript Crawling
- Automated Crawl Reports For Data Studio
- Advanced Search & Filtering and Translated UI
 OperaOpera 118.0 Build 5461.60 (64-bit)
OperaOpera 118.0 Build 5461.60 (64-bit) PC RepairPC Repair Tool 2025
PC RepairPC Repair Tool 2025 PhotoshopAdobe Photoshop CC 2025 26.6.0 (64-bit)
PhotoshopAdobe Photoshop CC 2025 26.6.0 (64-bit) OKXOKX - Buy Bitcoin or Ethereum
OKXOKX - Buy Bitcoin or Ethereum iTop VPNiTop VPN 6.4.0 - Fast, Safe & Secure
iTop VPNiTop VPN 6.4.0 - Fast, Safe & Secure Premiere ProAdobe Premiere Pro CC 2025 25.2.3
Premiere ProAdobe Premiere Pro CC 2025 25.2.3 BlueStacksBlueStacks 10.42.53.1001
BlueStacksBlueStacks 10.42.53.1001 Hero WarsHero Wars - Online Action Game
Hero WarsHero Wars - Online Action Game SemrushSemrush - Keyword Research Tool
SemrushSemrush - Keyword Research Tool LockWiperiMyFone LockWiper (Android) 5.7.2
LockWiperiMyFone LockWiper (Android) 5.7.2
Comments and User Reviews