-
Latest Version
-
Operating System
Windows 7 64 / Windows 8 64 / Windows 10 64 / Windows 11
-
User Rating
Click to vote -
Author / Product
-
Filename
postgresql-16.1-1-windows-x64.exe
Sometimes latest versions of the software can cause issues when installed on older devices or devices running an older version of the operating system.
Software makers usually fix these issues but it can take them some time. What you can do in the meantime is to download and install an older version of PostgreSQL 16.1.
For those interested in downloading the most recent release of PostgreSQL or reading our review, simply click here.
All old versions distributed on our website are completely virus-free and available for download at no cost.
We would love to hear from you
If you have any questions or ideas that you want to share with us - head over to our Contact page and let us know. We value your feedback!
-
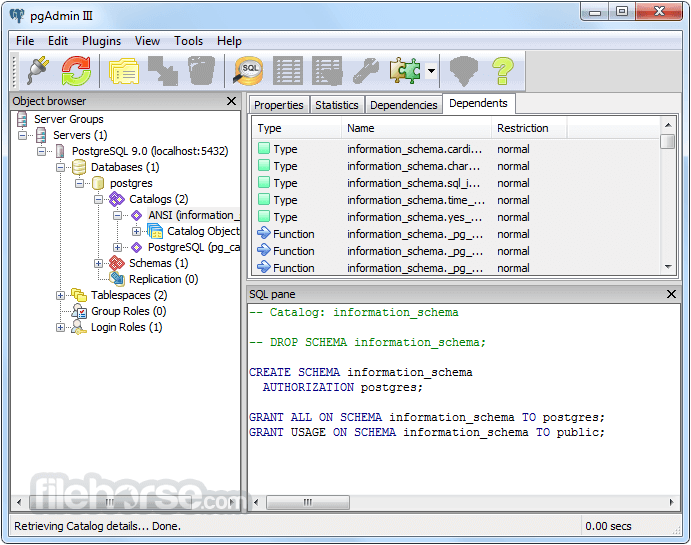
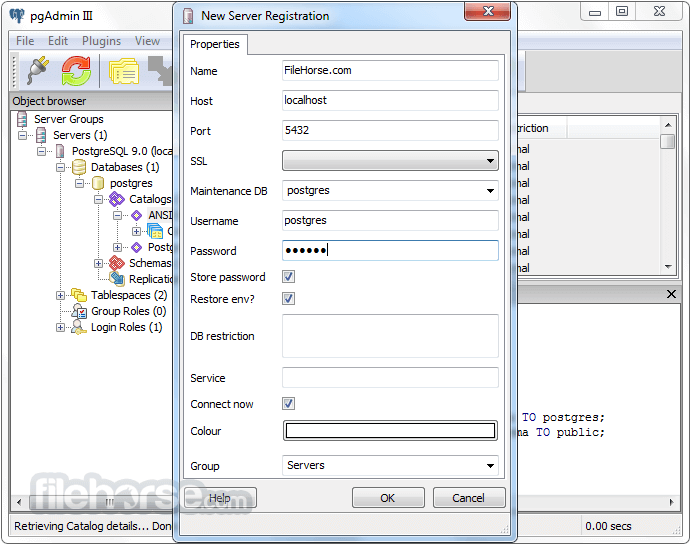
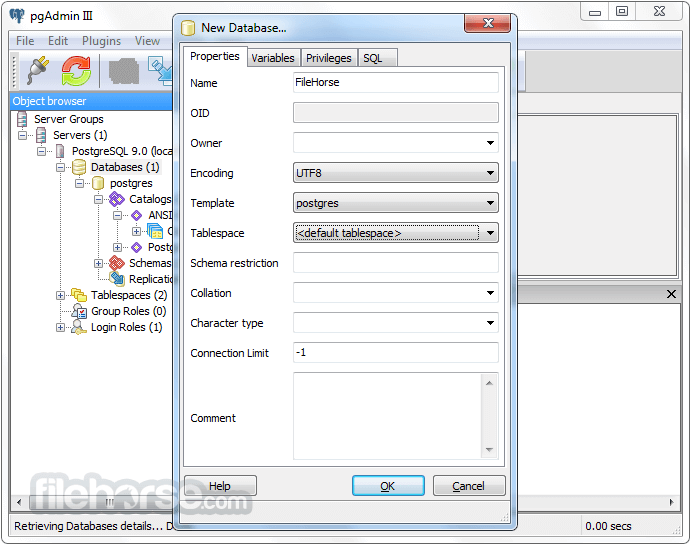
PostgreSQL 16.1 Screenshots
The images below have been resized. Click on them to view the screenshots in full size.
-
-
-

-

What's new in this version:
- However, several mistakes have been discovered that could lead to certain types of indexes yielding wrong search results or being unnecessarily inefficient. It is advisable to REINDEX potentially-affected indexes after installing this update. See the fourth through seventh changelog entries below.
- Fix handling of unknown-type arguments in DISTINCT "any" aggregate functions
- This error led to a text-type value being interpreted as an unknown-type value
- The PostgreSQL Project thanks Jingzhou Fu for reporting this problem
- Detect integer overflow while computing new array dimensions
- When assigning new elements to array subscripts that are outside the current array bounds, an undetected integer overflow could occur in edge cases. Memory stomps that are potentially exploitable for arbitrary code execution are possible, and so is disclosure of server memory.
- The PostgreSQL Project thanks Pedro Gallegos for reporting this problem
- Prevent the pg_signal_backend role from signalling background workers and autovacuum processes
- The documentation says that pg_signal_backend cannot issue signals to superuser-owned processes. It was able to signal these background processes, though, because they advertise a role OID of zero. Treat that as indicating superuser ownership. The security implications of cancelling one of these process types are fairly small so far as the core code goes
- Also ensure that the is_superuser parameter is set correctly in such processes. No specific security consequences are known for that oversight, but it might be significant for some extensions.
- The PostgreSQL Project thanks Hemanth Sandrana and Mahendrakar Srinivasarao for reporting this problem
- Fix misbehavior during recursive page split in GiST index build
- Fix a case where the location of a page downlink was incorrectly tracked, and introduce some logic to allow recovering from such situations rather than silently doing the wrong thing. This error could result in incorrect answers from subsequent index searches. It may be advisable to reindex all GiST indexes after installing this update.
- Prevent de-duplication of btree index entries for interval columns
- There are interval values that are distinguishable but compare equal, for example 24:00:00 and 1 day. This breaks assumptions made by btree de-duplication, so interval columns need to be excluded from de-duplication. This oversight can cause incorrect results from index-only scans. Moreover, after updating amcheck will report an error for almost all such indexes. Users should reindex any btree indexes on interval columns.
- Process date values more sanely in BRIN datetime_minmax_multi_ops indexes
- The distance calculation for dates was backward, causing poor decisions about which entries to merge. The index still produces correct results, but is much less efficient than it should be. Reindexing BRIN minmax_multi indexes on date columns is advisable.
- Process large timestamp and timestamptz values more sanely in BRIN datetime_minmax_multi_ops indexes
- Infinities were mistakenly treated as having distance zero rather than a large distance from other values, causing poor decisions about which entries to merge. Also, finite-but-very-large values
- Avoid calculation overflows in BRIN interval_minmax_multi_ops indexes with extreme interval values
- This bug might have caused unexpected failures while trying to insert large interval values into such an index.
- Fix partition step generation and runtime partition pruning for hash-partitioned tables with multiple partition keys
- Some cases involving an IS NULL condition on one of the partition keys could result in a crash.
- Fix inconsistent rechecking of concurrently-updated rows during MERGE
- In READ COMMITTED mode, an update that finds that its target row was just updated by a concurrent transaction will recheck the query's WHERE conditions on the updated row. MERGE failed to ensure that the proper rows of other joined tables were used during this recheck, possibly resulting in incorrect decisions about whether the newly-updated row should be updated again by MERGE.
- Correctly identify the target table in an inherited UPDATE/DELETE/MERGE even when the parent table is excluded by constraints
- If the initially-named table is excluded by constraints, but not all its inheritance descendants are, the first non-excluded descendant was identified as the primary target table. This would lead to firing statement-level triggers associated with that table, rather than the initially-named table as should happen. In v16, the same oversight could also lead to “invalid perminfoindex 0 in RTE with relid NNNN” errors.
- Fix edge case in btree mark/restore processing of ScalarArrayOpExpr clauses
- When restoring an indexscan to a previously marked position, the code could miss required setup steps if the scan had advanced exactly to the end of the matches for a ScalarArrayOpExpr
- Fix intra-query memory leak in Memoize execution
- Fix intra-query memory leak when a set-returning function repeatedly returns zero rows
- Don't crash if cursor_to_xmlschema() is applied to a non-data-returning Portal
- Fix improper sharing of origin filter condition across successive pg_logical_slot_get_changes() calls
- The origin condition set by one call of this function would be re-used by later calls that did not specify the origin argument. This was not intended.
- Throw the intended error if pgrowlocks() is applied to a partitioned table
- Previously, a not-on-point complaint “only heap AM is supported” would be raised.
- Handle invalid indexes more cleanly in assorted SQL functions
- Report an error if pgstatindex(), pgstatginindex(), pgstathashindex(), or pgstattuple() is applied to an invalid index. If brin_desummarize_range(), brin_summarize_new_values(), brin_summarize_range(), or gin_clean_pending_list() is applied to an invalid index, do nothing except to report a debug-level message. Formerly these functions attempted to process the index, and might fail in strange ways depending on what the failed CREATE INDEX had left behind.
- Avoid premature memory allocation failure with long inputs to to_tsvector()
- Fix over-allocation of the constructed tsvector in tsvectorrecv()
- If the incoming vector includes position data, the binary receive function left wasted space
- Improve checks for corrupt PGLZ compressed data
- Fix ALTER SUBSCRIPTION so that a commanded change in the run_as_owner option is actually applied
- Fix bulk table insertion into partitioned tables
- Improper sharing of insertion state across partitions could result in failures during COPY FROM, typically manifesting as “could not read block NNNN in file XXXX: read only 0 of 8192 bytes” errors.
- In COPY FROM, avoid evaluating column default values that will not be needed by the command
- This avoids a possible error if the default value isn't actually valid for the column, or if the default's expression would fail in the current execution context. Such edge cases sometimes arise while restoring dumps, for example. Previous releases did not fail in this situation, so prevent v16 from doing so.
- In COPY FROM, fail cleanly when an unsupported encoding conversion is needed
- Recent refactoring accidentally removed the intended error check for this, such that it ended in “cache lookup failed for function 0” instead of a useful error message.
- Avoid crash in EXPLAIN if a parameter marked to be displayed by EXPLAIN has a NULL boot-time value
- No built-in parameter fits this description, but an extension could define such a parameter.
- Ensure we have a snapshot while dropping ON COMMIT DROP temp tables
- This prevents possible misbehavior if any catalog entries for the temp tables have fields wide enough to require toasting
- Avoid improper response to shutdown signals in child processes just forked by system()
- This fix avoids a race condition in which a child process that has been forked off by system(), but hasn't yet exec'd the intended child program, might receive and act on a signal intended for the parent server process. That would lead to duplicate cleanup actions being performed, which will not end well.
- Cope with torn reads of pg_control in frontend programs
- On some file systems, reading pg_control may not be an atomic action when the server concurrently writes that file. This is detectable via a bad CRC. Retry a few times to see if the file becomes valid before we report error.
- Avoid torn reads of pg_control in relevant SQL functions
- Acquire the appropriate lock before reading pg_control, to ensure we get a consistent view of that file.
- Fix “could not find pathkey item to sort” errors occurring while planning aggregate functions with ORDER BY or DISTINCT options
- Avoid integer overflow when computing size of backend activity string array
- On 64-bit machines we will allow values of track_activity_query_size large enough to cause 32-bit overflow when multiplied by the allowed number of connections. The code actually allocating the per-backend local array was careless about this though, and allocated the array incorrectly.
- Fix briefly showing inconsistent progress statistics for ANALYZE on inherited tables
- The block-level counters should be reset to zero at the same time we update the current-relation field.
- Fix the background writer to report any WAL writes it makes to the statistics counters
- Fix confusion about forced-flush behavior in pgstat_report_wal()
- This could result in some statistics about WAL I/O being forgotten in a shutdown.
- Fix statistics tracking of temporary-table extensions
- These were counted as normal-table writes when they should be counted as temp-table writes.
- When track_io_timing is enabled, include the time taken by relation extension operations as write time
- Track the dependencies of cached CALL statements, and re-plan them when needed
- DDL commands, such as replacement of a function that has been inlined into a CALL argument, can create the need to re-plan a CALL that has been cached by PL/pgSQL. That was not happening, leading to misbehavior or strange errors such as “cache lookup failed”.
- Avoid a possible pfree-a-NULL-pointer crash after an error in OpenSSL connection setup
- Track nesting depth correctly when inspecting RECORD-type Vars from outer query levels
- This oversight could lead to assertion failures, core dumps, or “bogus varno” errors.
- Track hash function and negator function dependencies of ScalarArrayOpExpr plan nodes
- In most cases this oversight was harmless, since these functions would be unlikely to disappear while the node's original operator remains present.
- Fix error-handling bug in RECORD type cache management
- An out-of-memory error occurring at just the wrong point could leave behind inconsistent state that would lead to an infinite loop.
- Treat out-of-memory failures as fatal while reading WAL
- Previously this would be treated as a bogus-data condition, leading to the conclusion that we'd reached the end of WAL, which is incorrect and could lead to inconsistent WAL replay.
- Fix possible recovery failure due to trying to allocate memory based on a bogus WAL record length field
- Fix “could not duplicate handle” error occurring on Windows when min_dynamic_shared_memory is set above zero
- Fix order of operations in GenericXLogFinish
- This code violated the conditions required for crash safety by writing WAL before marking changed buffers dirty. No core code uses this function, but extensions do
- Remove incorrect assertion in PL/Python exception handling
- Fix pg_dump to dump the new run_as_owner option of subscriptions
- Due to this oversight, subscriptions would always be restored with run_as_owner set to false, which is not equivalent to their behavior in pre-v16 releases.
- Fix pg_restore so that selective restores will include both table-level and column-level ACLs for selected tables
- Formerly, only the table-level ACL would get restored if both types were present.
- Add logic to pg_upgrade to check for use of abstime, reltime, and tinterval data types
- These obsolete data types were removed in PostgreSQL version 12, so check to make sure they aren't present in an older database before claiming it can be upgraded.
- Avoid false “too many client connections” errors in pgbench on Windows
- Fix vacuumdb's handling of multiple -N switches
- Multiple -N switches should exclude tables in multiple schemas, but in fact excluded nothing due to faulty construction of a generated query.
- Fix vacuumdb to honor its --buffer-usage-limit option in analyze-only mode
- In contrib/amcheck, do not report interrupted page deletion as corruption
- This fix prevents false-positive reports of “the first child of leftmost target page is not leftmost of its level”, “block NNNN is not leftmost” or “left link/right link pair in index XXXX not in agreement”. They appeared if amcheck ran after an unfinished btree index page deletion and before VACUUM had cleaned things up.
- Fix failure of contrib/btree_gin indexes on interval columns, when an indexscan using the < or <= operator is performed
- Such an indexscan failed to return all the entries it should.
- Add support for LLVM 16 and 17
- Suppress assorted build-time warnings on recent macOS
- Xcode 15
- When building contrib/unaccent's rules file, fall back to using python if --with-python was not given and make variable PYTHON was not set
- Remove PHOT
- Presence of this abbreviation in the default list can cause failures on recent Debian and Ubuntu releases, as they no longer install the underlying tzdb entry by default. Since this is a made-up abbreviation for a zone with a total human population of about two dozen, it seems unlikely that anyone will miss it. If someone does, they can put it back via a custom abbreviations file.
 OperaOpera 125.0 Build 5729.21 (64-bit)
OperaOpera 125.0 Build 5729.21 (64-bit) MalwarebytesMalwarebytes Premium 5.4.5
MalwarebytesMalwarebytes Premium 5.4.5 PhotoshopAdobe Photoshop CC 2026 27.1 (64-bit)
PhotoshopAdobe Photoshop CC 2026 27.1 (64-bit) BlueStacksBlueStacks 10.42.153.1001
BlueStacksBlueStacks 10.42.153.1001 OKXOKX - Buy Bitcoin or Ethereum
OKXOKX - Buy Bitcoin or Ethereum Premiere ProAdobe Premiere Pro CC 2025 25.6.3
Premiere ProAdobe Premiere Pro CC 2025 25.6.3 PC RepairPC Repair Tool 2025
PC RepairPC Repair Tool 2025 Hero WarsHero Wars - Online Action Game
Hero WarsHero Wars - Online Action Game TradingViewTradingView - Trusted by 60 Million Traders
TradingViewTradingView - Trusted by 60 Million Traders Edraw AIEdraw AI - AI-Powered Visual Collaboration
Edraw AIEdraw AI - AI-Powered Visual Collaboration
Comments and User Reviews