-
Latest Version
-
Operating System
Windows 7 64 / Windows 8 64 / Windows 10 64 / Windows 11
-
User Rating
Click to vote -
Author / Product
-
Filename
postgresql-15.3-1-windows-x64.exe
Sometimes latest versions of the software can cause issues when installed on older devices or devices running an older version of the operating system.
Software makers usually fix these issues but it can take them some time. What you can do in the meantime is to download and install an older version of PostgreSQL 15.3.
For those interested in downloading the most recent release of PostgreSQL or reading our review, simply click here.
All old versions distributed on our website are completely virus-free and available for download at no cost.
We would love to hear from you
If you have any questions or ideas that you want to share with us - head over to our Contact page and let us know. We value your feedback!
-
PostgreSQL 15.3 Screenshots
The images below have been resized. Click on them to view the screenshots in full size.
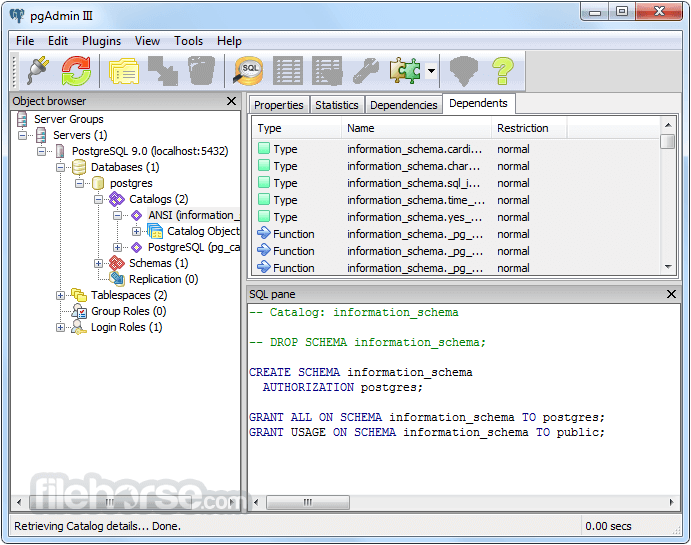
-
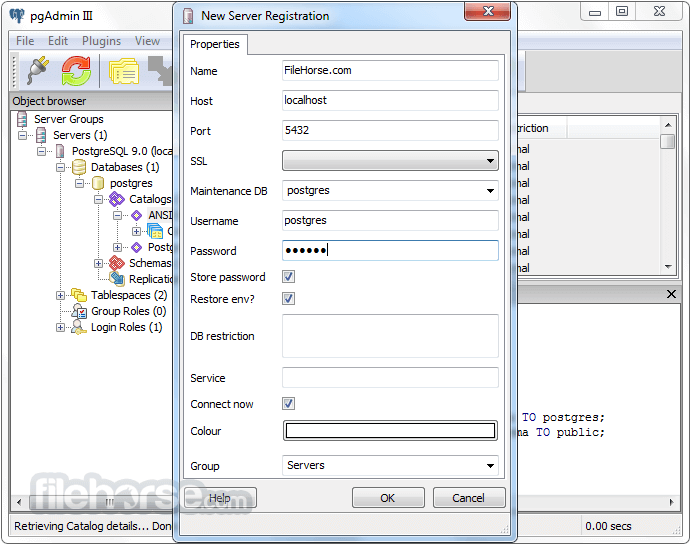
-
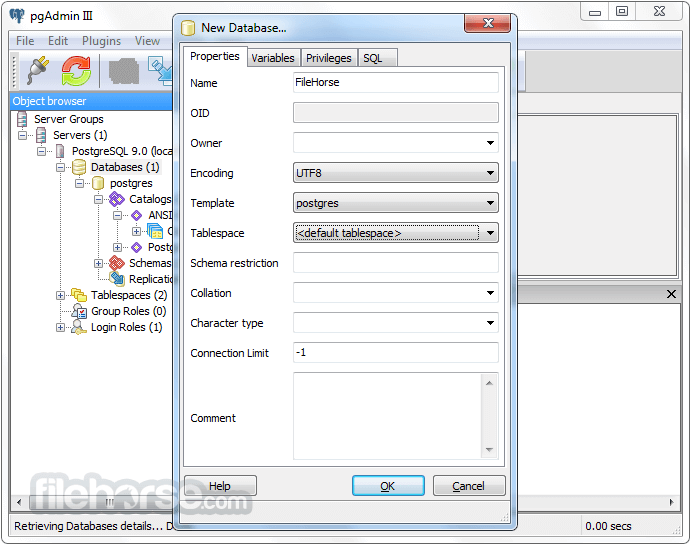
-

-

What's new in this version:
Changed:
- Prevent CREATE SCHEMA from defeating changes in search_path
- Within a CREATE SCHEMA command, objects in the prevailing search_path, as well as those in the newly-created schema, would be visible even within a called function or script that attempted to set a secure search_path. This could allow any user having permission to create a schema to hijack the privileges of a security definer function or extension script.
- The PostgreSQL Project thanks Alexander Lakhin for reporting this problem.
- Enforce row-level security policies correctly after inlining a set-returning function
- If a set-returning SQL-language function refers to a table having row-level security policies, and it can be inlined into a calling query, those RLS policies would not get enforced properly in some cases involving re-using a cached plan under a different role. This could allow a user to see or modify rows that should have been invisible.
- The PostgreSQL Project thanks Wolfgang Walther for reporting this problem.
- Fix potential corruption of the template
- Improper buffer handling created a risk that any later modification of the template's pg_class catalog would be lost.
- Ix memory leakage and unnecessary disk reads during CREATE DATABASE with the STRATEGY WAL_LOG option
- Avoid crash when the new schema name is omitted in CREATE SCHEMA
- The SQL standard allows writing CREATE SCHEMA AUTHORIZATION owner_name, with the schema name defaulting to owner_name. However some code paths expected the schema name to be present and would fail.
- Fix various planner failures with MERGE commands
- Planning could fail with errors like “variable not found in subplan target list” or “PlaceHolderVar found where not expected”.
- Fix the row count reported by MERGE for some corner cases
- The row count reported in the command tag counted rows that actually hadn't been modified due to a BEFORE ROW trigger returning NULL. This is inconsistent with what happens in plain UPDATE or DELETE, so change it to not count such rows. Also, avoid counting a row twice when MERGE moves it into a different partition of a partitioned table.
- Fix MERGE problems with concurrent updates
- Some cases misbehaved if a row to be updated or deleted by MERGE had just been updated by a concurrent transaction. This could lead to a crash, or the wrong merge action being executed, or no action at all.
- Add support for decompiling MERGE commands
- This was overlooked when MERGE was added, but it's essential support for MERGE in new-style SQL functions.
- Fix enabling/disabling of foreign-key triggers in partitioned tables
- ALTER TABLE ... ENABLE/DISABLE TRIGGER failed if applied to a partitioned table's foreign-key enforcement triggers, because it tried to locate the clone triggers for the partitions by name, and they do not have the same name. Locate them by parent-trigger OID instead.
- Disallow altering composite types that are stored in indexes
- ALTER TYPE disallows non-binary-compatible modifications of composite types if they are stored in any table columns.
- Disallow system columns as elements of foreign keys
- Since the removal of OID as a system column, there is no plausible use-case for this, and various bits of code no longer support it. Disallow it rather than trying to fix all the cases.
- Ensure that COPY TO from an RLS-enabled parent table does not copy any rows from child tables
- The documentation is quite clear that COPY TO copies rows from only the named table, not any inheritance children it may have. However, if row-level security was enabled on the table then this stopped being true.
- Avoid possible crash when array_position() or array_positions() is passed an empty array
- Fix possible out-of-bounds fetch in to_char()
- With bad luck this could have resulted in a server crash.
- Avoid buffer overread in translate() function
- When using the deletion feature, the function might fetch the byte just after the input string, creating a small risk of crash.
- Adjust text-search-related character classification logic to correctly detect whether the prevailing locale is C
- This code got confused if the database's default collation uses ICU.
- Avoid possible crash on empty input for type interval
- Re-allow exponential notation in ISO-8601 interval fields
- Interval input like P0.1e10D isn't officially sanctioned by ISO-8601, but we accepted it for a long time before version 15, so re-allow it.
- Fix error cursor setting for parse errors in JSON string literals
- Most cases in which a syntax error is detected in a string literal within a JSON value failed to set the error cursor appropriately. This led at least to an unhelpful error message
- Fix data corruption due to vacuum_defer_cleanup_age being larger than the current 64-bit xid
- In v14 and later with non-default settings of vacuum_defer_cleanup_age, it was possible to compute a very large vacuum cleanup horizon xid, leading to vacuum removing rows that are still live. v12 and v13 have a lesser form of the same problem affecting only GiST indexes, which could lead to index pages getting recycled too early.
- Fix parser's failure to detect some cases of improperly-nested aggregates
- This oversight could lead to executor failures for queries that should have been rejected as invalid.
- Fix data structure corruption during parsing of serial SEQUENCE NAME options
- This can lead to trouble if an event trigger captures the corrupted parse tree.
- Correctly update plan nodes' parallel-safety markings when moving initplans from one node to another
- This planner oversight could lead to “subplan was not initialized” errors at runtime.
- Avoid failure with PlaceHolderVars in extended-statistics code
- Use of dependency-type extended statistics could fail with “PlaceHolderVar found where not expected”.
- Fix incorrect tests for whether a qual clause applied to a subquery can be transformed into a window aggregate “run condition” within the subquery
- A SubPlan within such a clause would cause assertion failures or incorrect answers, as would some other unusual cases.
- Disable the inverse-transition optimization for window aggregates when the call contains sub-SELECTs
- This optimization requires that the aggregate's argument expressions have repeatable results, which might not hold for a sub-SELECT.
- Fix oversights in execution of nested ARRAY[] constructs
- Correctly detect overflow of the total space needed for the result array, avoiding a possible crash due to undersized output allocation. Also ensure that any trailing padding space in the result array is zeroed; while leaving garbage there is harmless for most purposes, it can result in odd behavior later.
- Prevent crash when updating a field within an array-of-domain-over-composite-type column
- Fix partition pruning logic for partitioning on boolean columns
- Pruning with a condition like boolcol IS NOT TRUE was done incorrectly, leading to possibly not returning rows in which boolcol is NULL. Also, the rather unlikely case of partitioning on NOT boolcol was handled incorrectly.
- Fix race condition in per-batch cleanup during parallel hash join
- A crash was possible given unlucky timing and parallel_leader_participation = off
- Recalculate GENERATED columns after an EvalPlanQual check
- In READ COMMITTED isolation mode, the effects of a row update might need to get reapplied to a newer version of the row than the query found originally. If so, we need to recompute any GENERATED columns, in case they depend on columns that were changed by the concurrent update.
- Fix memory leak in Memoize plan execution
- Fix buffer refcount leak when using batched inserts for a foreign table included in a partitioned tree
- Restore support for sub-millisecond vacuum_cost_delay settings
- Don't balance vacuum cost delay when a table has a per-relation vacuum_cost_delay setting of zero
- Delay balancing is supposed to be disabled whenever autovacuum is processing a table with a per-relation vacuum_cost_delay setting, but this was done only for positive settings, not zero.
- Fix corner-case crashes when columns have been added to the end of a view
- Repair rare failure of MULTIEXPR_SUBLINK subplans in partitioned updates
- Use of the syntax INSERT ... ON CONFLICT DO UPDATE SET
- Fix handling of DEFAULT markers within a multi-row INSERT ... VALUES query on a view that has a DO ALSO INSERT ... SELECT rule
- Such cases typically failed with “unrecognized node type” errors or assertion failures.
- Support references to OLD and NEW within subqueries in rule actions
- Such references are really lateral references, but the server could crash if the subquery wasn't explicitly marked with LATERAL. Arrange to do that implicitly when necessary.
- When decompiling a rule or SQL function body containing INSERT/UPDATE/DELETE within WITH, take care to print the correct alias for the target table
- Fix glitches in SERIALIZABLE READ ONLY optimization
- Transactions already marked as “doomed” confused the safe-snapshot optimization for SERIALIZABLE READ ONLY transactions. The optimization was unnecessarily skipped in some cases. In other cases an assertion failure occurred
- Avoid leaking cache callback slots in the pgoutput logical decoding plugin
- Multiple cycles of starting up and shutting down the plugin within a single session would eventually lead to an “out of relcache_callback_list slots” error.
- Avoid unnecessary calls to custom validators for index operator class options
- This change fixes some cases where an unexpected error was thrown.
- Avoid useless work while scanning a multi-column BRIN index with multiple scan keys
- The existing code effectively considered only the last scan key while deciding whether a range matched, thus usually scanning more of the index than it needed to.
- Fix netmask handling in BRIN inet_minmax_multi_ops opclass
- This error triggered an assertion failure in assert-enabled builds, but is mostly harmless in production builds
- Fix dereference of dangling pointer during buffering build of a GiST index
- This error seems to usually be harmless in production builds, as the fetched value is noncritical; but in principle it could cause a server crash
- Ignore dropped columns and generated columns during logical replication of an update or delete action
- Replication with the REPLICA IDENTITY FULL option failed if the table contained such columns
- Correct the name of the wait event for SLRU buffer I/O for commit timestamps
- This wait event is named CommitTsBuffer according to the documentation, but the code had it as CommitTSBuffer. Change the code to match the documentation, as that way is more consistent with the naming of related wait events.
- Re-activate reporting of wait event SLRUFlushSync
- Reporting of this type of wait was accidentally removed in code refactoring.
- Avoid possible underflow when calculating how many WAL segments to keep
- This could result in not honoring wal_keep_size accurately
- Disable startup progress reporting overhead in standby mode
- In standby mode, we don't actually report progress of recovery, but we were doing work to track it anyway
- Support RSA-PSS certificates with SCRAM-SHA-256 channel binding
- This feature requires building with OpenSSL 1.1.1 or newer. Both the server and libpq are affected.
- Avoid race condition with process ID tracking on Windows
- The operating system could recycle a PID before the postmaster observed that that child process was gone. This could lead to tracking more than one child with the same PID, resulting in confusion.
- Fix list_copy_head() to work correctly on an empty List
- This case is not known to be reached by any core PostgreSQL code, but extensions might rely on it working
- Add missing cases to SPI_result_code_string()
- Fix erroneous Valgrind markings in AllocSetRealloc()
- In the unusual case where the size of a large
- Fix assertion failure for MERGE into a partitioned table with row-level security enabled
- Avoid assertion failure when decoding a transactional logical replication message
- Avoid locale sensitivity when processing regular expression escapes
- A backslash followed by a non-ASCII character could sometimes cause an assertion failure, depending on the prevailing locale.
- Avoid trying to write an empty WAL record in log_newpage_range() when the last few pages in the specified range are empty
- It is not entirely clear whether this case is reachable in released branches, but if it is then an assertion failure could occur.
- Fix session-lifespan memory leakage in plpgsql DO blocks that use cast expressions
- Tighten array dimensionality checks when converting Perl list structures to multi-dimensional SQL arrays
- Plperl could misbehave when the nesting of sub-lists is inconsistent so that the data does not represent a rectangular array of values. Such cases now produce errors, but previously they could result in a crash or garbage output.
- Tighten array dimensionality checks when converting Python list structures to multi-dimensional SQL arrays
- Plpython could misbehave when dealing with empty sub-lists, or when the nesting of sub-lists is inconsistent so that the data does not represent a rectangular array of values. The former should result in an empty output array, and the latter in an error. But some cases resulted in a crash, and others in unexpected output.
- Fix unwinding of exception stack in plpython
- Some rare failure cases could return without cleaning up the PG_TRY exception stack, risking a crash if another error was raised before the next stack level was unwound.
- Fix inconsistent GSS-encryption error handling in libpq's PQconnectPoll()
- With gssencmode set to require, the connection was not marked dead after a GSS initialization failure. Make it fail immediately, as the equivalent case for TLS encryption has long done.
- Fix possible data corruption in ecpg programs built with the -C ORACLE option
- When ecpg_get_data() is called with varcharsize set to zero, it could write a terminating zero character into the last byte of the preceding field, truncating the data in that field.
- Fix pg_dump so that partitioned tables that are hash-partitioned on an enum-type column can be restored successfully
- Since the hash codes for enum values depend on the OIDs assigned to the enum, they are typically different after a dump and restore, meaning that rows often need to go into a different partition than they were in originally. Users can work around that by specifying the --load-via-partition-root option; but since there is very little chance of success without that, teach pg_dump to apply it automatically to such tables.
- Also, fix pg_restore to not try to TRUNCATE target tables before restoring into them when --load-via-partition-root mode is used. This avoids a hazard of deadlocks and lost data.
- Correctly detect non-seekable files on Windows
- This bug led to misbehavior when pg_dump writes to a pipe or pg_restore reads from one.
- In pgbench's “prepared” mode, prepare all the commands in a pipeline before starting the pipeline
- This avoids a failure when a pgbench script tries to start a serializable transaction inside a pipeline.
- In contrib/amcheck's heap checking code, deal correctly with tuples having zero xmin or xmax
- In contrib/amcheck, deal sanely with xids that appear to be before epoch zero
- In cases of corruption we might see a wrapped-around 32-bit xid that appears to be before the first xid epoch. Promoting such a value to 64-bit form produced a value far in the future, resulting in wrong reports. Return FirstNormalFullTransactionId in such cases so that things work reasonably sanely.
- In contrib/basebackup_to_shell, properly detect failure to open a pipe
- In contrib/hstore_plpython, avoid crashing if the Python value to be transformed isn't a mapping
- This should give an error, but Python 3 changed some APIs in a way that caused the check to misbehave, allowing a crash to ensue.
- Require the siglen option of a GiST index on an ltree column, if specified, to be a multiple of 4
- Other values result in misaligned accesses to index content, which is harmless on Intel-compatible hardware but can cause a crash on some other architectures.
- In contrib/pageinspect, add defenses against incorrect input for the gist_page_items() function
- Fix misbehavior in contrib/pg_trgm with an unsatisfiable regular expression
- A regex such as $foo is legal but unsatisfiable; the regex compiler recognizes that and produces an empty NFA graph. Attempting to optimize such a graph into a pg_trgm GIN or GiST index qualification resulted in accessing off the end of a work array, possibly leading to crashes.
- Fix handling of escape sequences in contrib/postgres_fdw's application_name parameter
- The code to expand these could fail if executed in a background process, as for example during auto-analyze of a foreign table.
- In contrib/pg_walinspect, limit memory usage of pg_get_wal_records_info()
- Use the --strip-unneeded option when stripping static libraries with GNU-compatible strip
- Previously, make install-strip used the -x option in this case. This change avoids misbehavior of llvm-strip, and gives slightly smaller output as well.
- Stop recommending auto-download of DTD files for building the documentation, and indeed disable it
- It appears no longer possible to build the SGML documentation without a local installation of the DocBook DTD files. Formerly xsltproc could download those files on-the-fly from sourceforge.net; but sourceforge.net now permits only HTTPS access, and no common version of xsltproc supports that. Hence, remove the bits of our documentation suggesting that that's possible or useful, and instead add xsltproc's --nonet option to the build recipes.
- When running TAP tests in PGXS builds, use a saner location for the temporary portlock directory
- Place it under tmp_check in the build directory. With the previous coding, a PGXS build would try to place it in the installation directory, which is not necessarily writable.
- Update time zone data files to tzdata release 2023c for DST law changes in Egypt, Greenland, Morocco, and Palestine.
- When observing Moscow time, Europe/Kirov and Europe/Volgograd now use the abbreviations MSK/MSD instead of numeric abbreviations, for consistency with other timezones observing Moscow time. Also, America/Yellowknife is no longer distinct from America/Edmonton; this affects some pre-1948 timestamps in that area.
 OperaOpera 125.0 Build 5729.21 (64-bit)
OperaOpera 125.0 Build 5729.21 (64-bit) MalwarebytesMalwarebytes Premium 5.4.5
MalwarebytesMalwarebytes Premium 5.4.5 PhotoshopAdobe Photoshop CC 2026 27.1 (64-bit)
PhotoshopAdobe Photoshop CC 2026 27.1 (64-bit) BlueStacksBlueStacks 10.42.153.1001
BlueStacksBlueStacks 10.42.153.1001 OKXOKX - Buy Bitcoin or Ethereum
OKXOKX - Buy Bitcoin or Ethereum Premiere ProAdobe Premiere Pro CC 2025 25.6.3
Premiere ProAdobe Premiere Pro CC 2025 25.6.3 PC RepairPC Repair Tool 2025
PC RepairPC Repair Tool 2025 Hero WarsHero Wars - Online Action Game
Hero WarsHero Wars - Online Action Game TradingViewTradingView - Trusted by 60 Million Traders
TradingViewTradingView - Trusted by 60 Million Traders Edraw AIEdraw AI - AI-Powered Visual Collaboration
Edraw AIEdraw AI - AI-Powered Visual Collaboration
Comments and User Reviews