-
Latest Version
-
Operating System
Windows XP64 / Vista64 / Windows 7 64 / Windows 8 64 / Windows 10 64
-
User Rating
Click to vote -
Author / Product
-
Filename
postgresql-13.2-1-windows-x64.exe
Sometimes latest versions of the software can cause issues when installed on older devices or devices running an older version of the operating system.
Software makers usually fix these issues but it can take them some time. What you can do in the meantime is to download and install an older version of PostgreSQL 13.2.
For those interested in downloading the most recent release of PostgreSQL or reading our review, simply click here.
All old versions distributed on our website are completely virus-free and available for download at no cost.
We would love to hear from you
If you have any questions or ideas that you want to share with us - head over to our Contact page and let us know. We value your feedback!
-
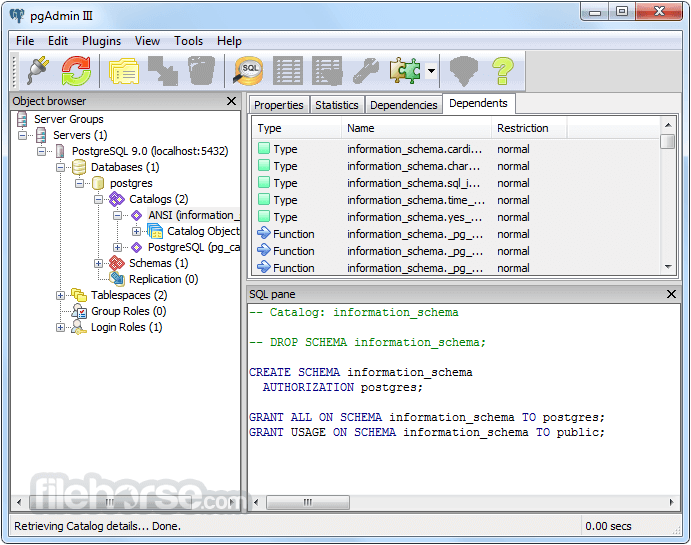
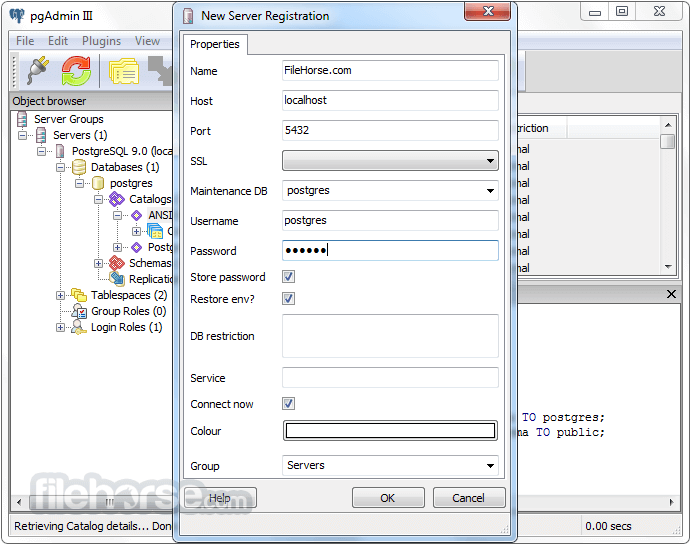
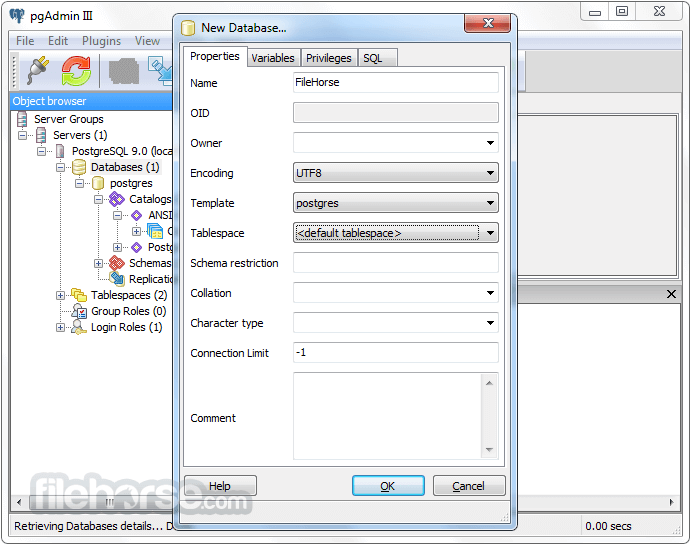
PostgreSQL 13.2 Screenshots
The images below have been resized. Click on them to view the screenshots in full size.
-
-
-

-

What's new in this version:
- Fix failure to check per-column SELECT privileges in some join queries
- In some cases involving joins, the parser failed to record all the columns read by a query in the column-usage bitmaps that are used for permissions checking. Although the executor would still insist on some sort of SELECT privilege to run the query, this meant that a user having SELECT privilege on only one column of a table could nonetheless read all its columns through a suitably crafted query.
- A stored view that is subject to this problem will have incomplete column-usage bitmaps, and thus permissions will still not be enforced properly on the view after updating. In installations that depend on column-level permissions for security, it is recommended to CREATE OR REPLACE all user-defined views to cause them to be re-parsed.
- The PostgreSQL Project thanks Sven Klemm for reporting this problem. (CVE-2021-20229)
- Fix information leakage in constraint-violation error messages
- If an UPDATE command attempts to move a row to a different partition but finds that it violates some constraint on the new partition, and the columns in that partition are in different physical positions than in the parent table, the error message could reveal the contents of columns that the user does not have SELECT privilege on. (CVE-2021-3393)
- Fix incorrect detection of concurrent page splits while inserting into a GiST index
- Concurrent insertions could lead to a corrupt index with entries placed in the wrong pages. It's recommended to reindex any GiST index that's been subject to concurrent insertions.
- Fix CREATE INDEX CONCURRENTLY to wait for concurrent prepared transactions
- At the point where CREATE INDEX CONCURRENTLY waits for all concurrent transactions to complete so that it can see rows they inserted, it must also wait for all prepared transactions to complete, for the same reason. Its failure to do so meant that rows inserted by prepared transactions might be omitted from the new index, causing queries relying on the index to miss such rows. In installations that have enabled prepared transactions (max_prepared_transactions > 0), it's recommended to reindex any concurrently-built indexes in case this problem occurred when they were built.
- Avoid crash when trying to rescan an aggregation plan node that has both hashed and sorted grouping sets
- Fix possible incorrect query results when a hash aggregation node spills some tuples to disk
- It was possible for aggregation grouping values to be replaced by nulls when the tuples are read back in, leading to wrong answers.
- Fix edge case in incremental sort
- If the last tuple of a sort batch chanced to be the first tuple of the next group of already-sorted tuples, the code did the wrong thing. This could lead to “retrieved too many tuples in a bounded sort” error messages, or to silently-wrong sorting results.
- Avoid crash when a CALL or DO statement that performs a transaction rollback is executed via extended query protocol
- In PostgreSQL 13, this case reliably caused a null-pointer dereference. In earlier versions the bug seems to have no visible symptoms, but it's not quite clear that it could never cause a problem.
- Avoid unnecessary errors with BEFORE UPDATE triggers on partitioned tables
- A BEFORE UPDATE FOR EACH ROW trigger that modified the row in any way prevented UPDATE from moving the row to another partition when needed; but there is no longer any reason for this restriction.
- Fix partition pruning logic to handle asymmetric hash partition sets
- If a hash-partitioned table has unequally-sized partitions (that is, varying modulus values), or it lacks partitions for some remainder values, then the planner's pruning logic could mistakenly conclude that some partitions don't need to be scanned, leading to failure to find rows that the query should find.
- Avoid incorrect results when WHERE CURRENT OF is applied to a cursor whose plan contains a MergeAppend node
- This case is unsupported (in general, a cursor using ORDER BY is not guaranteed to be simply updatable); but the code previously did not reject it, and could silently give false matches.
- Fix crash when WHERE CURRENT OF is applied to a cursor whose plan contains a custom scan node
- Fix planner's mishandling of placeholders whose evaluation should be delayed by an outer join
- This occurs in particular with trivial subqueries containing lateral references to outer-join outputs. The mistake could result in a malformed plan. The known cases trigger a “failed to assign all NestLoopParams to plan nodes” error, but other symptoms may be possible.
- Fix planner's handling of placeholders during removal of useless RESULT RTEs
- This oversight could lead to “no relation entry for relid N” planner errors.
- Fix planner's handling of a placeholder that is computed at some join level and used only at that same level
- This oversight could lead to “failed to build any N-way joins” planner errors.
- Consider unsorted subpaths when planning a Gather Merge operation
- It's possible to use such a path by adding an explicit Sort node, and in some cases that gives rise to a superior plan.
- Do not consider ORDER BY expressions involving parallel-restricted functions or set-returning functions when trying to parallelize sorts
- Such cases cannot safely be pushed into worker processes, but the incremental sort feature accidentally made us consider them.
- Be more careful about whether index AMs support mark/restore
- This prevents errors about missing support functions in rare edge cases.
- Fix overestimate of the amount of shared memory needed for parallel queries
- Fix ALTER DEFAULT PRIVILEGES to handle duplicated arguments safely
- Duplicate role or schema names within the same command could lead to “tuple already updated by self” errors or unique-constraint violations.
- Flush ACL-related caches when pg_authid changes
- This change ensures that permissions-related decisions will promptly reflect the results of ALTER ROLE ... [NO] INHERIT.
- Fix failure to detect “snapshot too old” conditions in tables rewritten in the current transaction
- This is only a hazard when wal_level is set to minimal and the rewrite is performed by ALTER TABLE SET TABLESPACE.
- Fix spurious failure of CREATE PUBLICATION when applied to a table created or rewritten in the current transaction
- This is only a hazard when wal_level is set to minimal.
- Prevent misprocessing of ambiguous CREATE TABLE LIKE clauses
- A LIKE clause is re-examined after initial creation of the new table, to handle importation of indexes and such. It was possible for this re-examination to find a different table of the same name, causing unexpected behavior; one example is where the new table is a temporary table of the same name as the LIKE target.
- Rearrange order of operations in CREATE TABLE LIKE so that indexes are cloned before building foreign key constraints
- This fixes the case where a self-referential foreign key constraint declared in the outer CREATE TABLE depends on an index that's coming from the LIKE clause.
- Disallow CREATE STATISTICS on system catalogs
- Disallow converting an inheritance child table to a view
- Ensure that disk space allocated for a dropped relation is released promptly at commit
- Previously, if the dropped relation spanned multiple 1GB segments, only the first segment was truncated immediately. Other segments were simply unlinked, which doesn't authorize the kernel to release the storage so long as any other backends still have the files open.
- Prevent dropping a tablespace that is referenced by a partitioned relation, but is not used for any actual storage
- Previously this was allowed, but subsequent operations on the partitioned relation would fail.
- Fix progress reporting for CLUSTER
- Fix handling of backslash-escaped multibyte characters in COPY FROM
- A backslash followed by a multibyte character was not handled correctly. In some client character encodings, this could lead to misinterpreting part of a multibyte character as a field separator or end-of-copy-data marker.
- Avoid preallocating executor hash tables in EXPLAIN without ANALYZE
- Fix recently-introduced race condition in LISTEN/NOTIFY queue handling
- A newly-listening backend could attempt to read SLRU pages that were in process of being truncated, possibly causing an error.
- Allow the jsonb concatenation operator to handle all combinations of JSON data types
- We can concatenate two JSON objects or two JSON arrays. Handle other cases by wrapping non-array inputs in one-element arrays, then performing an array concatenation. Previously, some combinations of inputs followed this rule but others arbitrarily threw an error.
- Fix use of uninitialized value while parsing a * quantifier in a BRE-mode regular expression
- This error could cause the quantifier to act non-greedy, that is behave like a *? quantifier would do in full regular expressions.
- Fix numeric power() for the case where the exponent is exactly INT_MIN (-2147483648)
- Previously, a result with no significant digits was produced.
- Fix integer-overflow cases in substring() functions
- If the specified starting index and length overflow an integer when added together, substring() misbehaved, either throwing a bogus “negative substring length” error for a case that should succeed, or failing to complain that a negative length is negative (and instead returning the whole string, in most cases).
- Prevent possible data loss from incorrect detection of the wraparound point of an SLRU log
- The wraparound point typically falls in the middle of a page, which must be rounded off to a page boundary, and that was not done correctly. No issue could arise unless an installation had gotten to within one page of SLRU overflow, which is unlikely in a properly-functioning system. If this did happen, it would manifest in later “apparent wraparound” or “could not access status of transaction” errors.
- Fix WAL-reading logic to handle timeline switches correctly
- Previously, if WAL archiving is enabled, a standby could fail to follow a primary running on a newer timeline, with errors like “requested WAL segment has already been removed”.
- Fix memory leak in walsender processes while sending new snapshots for logical decoding
- Fix relation cache leak in walsender processes while sending row changes via the root of a partitioned relation during logical replication (Amit Langote, Mark Zhao)
- Fix walsender to accept additional commands after terminating replication
- Ensure detection of deadlocks between hot standby backends and the startup (WAL-application) process
- The startup process did not run the deadlock detection code, so that in situations where the startup process is last to join a circular wait situation, the deadlock might never be recognized.
- Fix possible failure to detect recovery conflicts while deleting an index entry that references a HOT chain
- The code failed to traverse the HOT chain and might thus compute a too-old XID horizon, which could lead to incorrect conflict processing in hot standby. The practical impact of this bug is limited; in most cases the correct XID horizon would be found anyway from nearby operations.
- Ensure that a nonempty value of krb_server_keyfile always overrides any setting of KRB5_KTNAME in the server's environment
- Previously, which setting took precedence depended on whether the client requests GSS encryption.
- In server log messages about failing to match connections to pg_hba.conf entries, include details about whether GSS encryption has been activated
- This is relevant data if hostgssenc or hostnogssenc entries exist.
- Fix assorted issues in server's support for GSS encryption
- Remove pointless restriction that only GSS authentication can be used on a GSS-encrypted connection. Add GSS encryption information to connection-authorized log messages. Include GSS-related space when computing the required size of shared memory (this omission could have caused problems with very high max_connections settings). Avoid possible infinite recursion when reporting an unrecoverable GSS encryption error.
- Ensure that unserviced requests for background workers are cleaned up when the postmaster begins a “smart” or “fast” shutdown sequence
- Previously, there was a race condition whereby a child process that had requested a background worker just before shutdown could wait indefinitely, preventing shutdown from completing.
- Fix portability problem in parsing of recovery_target_xid values
- The target XID is potentially 64 bits wide, but it was parsed with strtoul(), causing misbehavior on platforms where long is 32 bits (such as Windows).
- Avoid trying to use parallel index build in a standalone backend
- Allow index AMs to support included columns without necessarily supporting multiple key columns
- While taking a base backup, avoid executing any SHA256 code if a backup manifest is not needed
- When using OpenSSL operating in FIPS mode, SHA256 hashing is rejected, leading to an error. This change makes it possible to take a base backup on such a platform, so long as --no-manifest is specified.
- Avoid assertion failure during parallel aggregation of an aggregate with a non-strict deserialization function
- No such aggregate functions exist in core PostgreSQL, but some extensions such as PostGIS provide some. The mistake is harmless anyway in a non-assert build.
- Avoid assertion failure in pg_get_functiondef() when examining a function with a TRANSFORM option
- Fix data structure misallocation in PL/pgSQL's CALL statement
- A CALL in a PL/pgSQL procedure, to another procedure that has OUT parameters, would fail if the called procedure did a COMMIT or ROLLBACK.
- In libpq, do not skip trying SSL after GSS encryption
- If we successfully made a GSS-encrypted connection, but then failed during authentication, we would fall back to an unencrypted connection rather than next trying an SSL-encrypted connection. This could lead to unexpected connection failure, or to silently getting an unencrypted connection where an encrypted one is expected. Fortunately, GSS encryption could only succeed if both client and server hold valid tickets in the same Kerberos infrastructure. It seems unlikely for that to be true in an environment that requires SSL encryption instead.
- Make libpq's PQconndefaults() function report the correct default value for channel_binding
- In psql, re-allow including a password in a connection_string argument of a connect command
- This used to work, but a recent bug fix caused the password to be ignored (resulting in prompting for a password).
- In psql's d commands, don't truncate the display of column default values
- Formerly, they were arbitrarily truncated at 128 characters.
- Fix assorted bugs in psql's help command
- help with two argument words failed to find a command description using only the first word, for example help reset all should show the help for RESET but did not. Also, help often failed to invoke the pager when it should. It also leaked memory.
- Fix pg_dump's dumping of inherited generated columns
- The previous behavior resulted in (harmless) errors during restore.
- In pg_dump, ensure that the restore script runs ALTER PUBLICATION ADD TABLE commands as the owner of the publication, and similarly runs ALTER INDEX ATTACH PARTITION commands as the owner of the partitioned index
- Previously, these commands would be run by the role that started the restore script; which will usually work, but in corner cases that role might not have adequate permissions.
- Fix pg_dump to handle WITH GRANT OPTION in an extension's initial privileges
- If an extension's script creates an object and grants privileges on it with grant option, then later the user revokes such privileges, pg_dump would generate incorrect SQL for reproducing the situation. (Few if any extensions do this today.)
- In pg_rewind, ensure that all WAL is accounted for when rewinding a standby server
- In pgbench, disallow a digit as the first character of a variable name
- This prevents trying to substitute variables into timestamp literal values, which may contain strings like 12:34.
- Report the correct database name in connection failure error messages from some client programs
- If the database name was defaulted rather than given on the command line, pg_dumpall, pgbench, oid2name, and vacuumlo would produce misleading error messages after a connection failure.
- Fix memory leak in contrib/auto_explain
- Memory consumed while producing the EXPLAIN output was not freed until the end of the current transaction (for a top-level statement) or the end of the surrounding statement (for a nested statement). This was particularly a problem with log_nested_statements enabled.
- In contrib/postgres_fdw, avoid leaking open connections to remote servers when a user mapping or foreign server object is dropped
- Open connections that depend on a dropped user mapping or foreign server can no longer be referenced, but formerly they were kept around anyway for the duration of the local session.
- Fix faulty assertion in contrib/postgres_fdw
- In contrib/pgcrypto, check for error returns from OpenSSL's EVP functions
- We do not really expect errors here, but this change silences warnings from static analysis tools.
- Make contrib/pg_prewarm more robust when the cluster is shut down before prewarming is complete
- Previously, autoprewarm would rewrite its status file with only the block numbers that it had managed to load so far, thus perhaps largely disabling the prewarm functionality in the next startup. Instead, suppress status file updates until the initial loading pass is complete.
- In contrib/pg_trgm's GiST index support, avoid crash in the rare case that picksplit is called on exactly two index items
- Fix miscalculation of timeouts in contrib/pg_prewarm and contrib/postgres_fdw
- The main loop in contrib/pg_prewarm's autoprewarm parent process underestimated its desired sleep time by a factor of 1000, causing it to consume much more CPU than intended. When waiting for a result from a remote server, contrib/postgres_fdw overestimated the desired timeout by a factor of 1000 (though this error had been mitigated by imposing a clamp to 60 seconds).
- Both of these errors stemmed from incorrectly converting seconds-and-microseconds to milliseconds. Introduce a new API TimestampDifferenceMilliseconds() to make it easier to get this right in the future.
- Improve configure's heuristics for selecting PG_SYSROOT on macOS
- The new method is more likely to produce desirable results when Xcode is newer than the underlying operating system. Choosing a sysroot that does not match the OS version may result in nonfunctional executables.
- While building on macOS, specify -isysroot in link steps as well as compile steps
- This likewise improves the results when Xcode is out of sync with the operating system.
- Fix JIT compilation to be compatible with LLVM 11 and LLVM 12
- Fix potential mishandling of references to boolean variables in JIT expression compilation
- No field reports attributable to this have been seen, but it seems likely that it could cause problems on some architectures.
- Fix compile failure with ICU 68 and later
- Avoid memcpy() with a NULL source pointer and zero count during partitioned index creation
- While such a call is not known to cause problems in itself, some compilers assume that the arguments of memcpy() are never NULL, which could result in incorrect optimization of nearby code.
- Update time zone data files to tzdata release 2021a for DST law changes in Russia (Volgograd zone) and South Sudan, plus historical corrections for Australia, Bahamas, Belize, Bermuda, Ghana, Israel, Kenya, Nigeria, Palestine, Seychelles, and Vanuatu.
- Notably, the Australia/Currie zone has been corrected to the point where it is identical to Australia/Hobart.
 OperaOpera 117.0 Build 5408.35 (64-bit)
OperaOpera 117.0 Build 5408.35 (64-bit) PC RepairPC Repair Tool 2025
PC RepairPC Repair Tool 2025 PhotoshopAdobe Photoshop CC 2025 26.3 (64-bit)
PhotoshopAdobe Photoshop CC 2025 26.3 (64-bit) OKXOKX - Buy Bitcoin or Ethereum
OKXOKX - Buy Bitcoin or Ethereum iTop VPNiTop VPN 6.3.0 - Fast, Safe & Secure
iTop VPNiTop VPN 6.3.0 - Fast, Safe & Secure Premiere ProAdobe Premiere Pro CC 2025 25.1
Premiere ProAdobe Premiere Pro CC 2025 25.1 BlueStacksBlueStacks 10.41.661.1001
BlueStacksBlueStacks 10.41.661.1001 Hero WarsHero Wars - Online Action Game
Hero WarsHero Wars - Online Action Game TradingViewTradingView - Trusted by 60 Million Traders
TradingViewTradingView - Trusted by 60 Million Traders LockWiperiMyFone LockWiper (Android) 5.7.2
LockWiperiMyFone LockWiper (Android) 5.7.2
Comments and User Reviews