-
Latest Version
-
Operating System
Windows XP64 / Vista64 / Windows 7 64 / Windows 8 64 / Windows 10 64
-
User Rating
Click to vote -
Author / Product
-
Filename
postgresql-13.0-1-windows-x64.exe
Sometimes latest versions of the software can cause issues when installed on older devices or devices running an older version of the operating system.
Software makers usually fix these issues but it can take them some time. What you can do in the meantime is to download and install an older version of PostgreSQL 13.0.
For those interested in downloading the most recent release of PostgreSQL or reading our review, simply click here.
All old versions distributed on our website are completely virus-free and available for download at no cost.
We would love to hear from you
If you have any questions or ideas that you want to share with us - head over to our Contact page and let us know. We value your feedback!
-
PostgreSQL 13.0 Screenshots
The images below have been resized. Click on them to view the screenshots in full size.
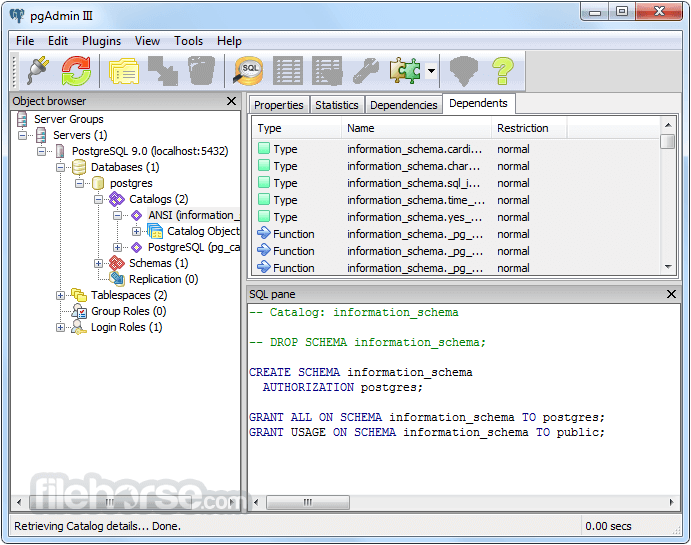
-
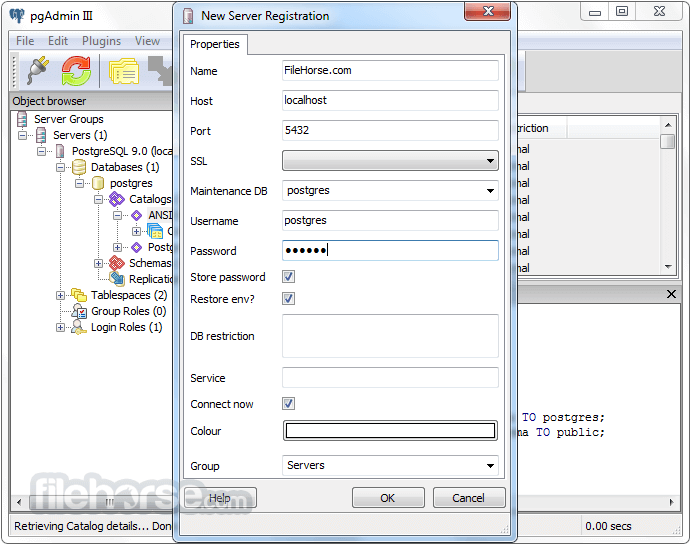
-
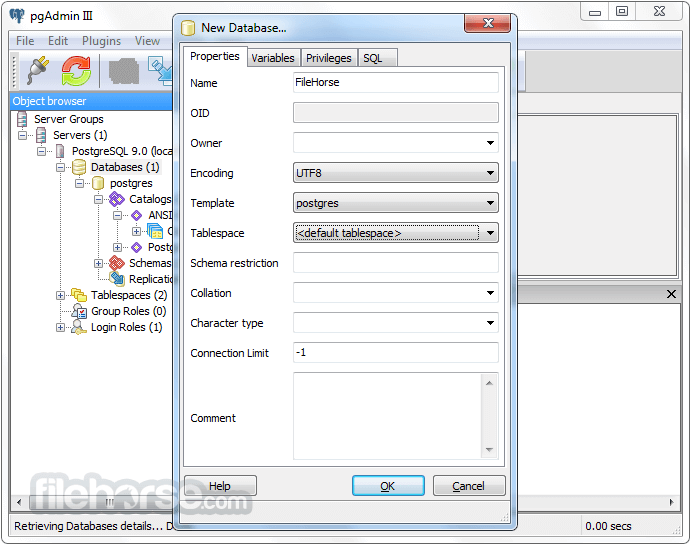
-

-

What's new in this version:
Server:
Partitioning:
- Allow pruning of partitions to happen in more cases
- Allow partitionwise joins to happen in more cases
- For example, partitionwise joins can now happen between partitioned tables even when their partition bounds do not match exactly
- Support row-level BEFORE triggers on partitioned tables
- However, such a trigger is not allowed to change which partition is the destination
- Allow partitioned tables to be logically replicated via publications
- Previously, partitions had to be replicated individually. Now a partitioned table can be published explicitly, causing all its partitions to be published automatically. Addition/removal of a partition causes it to be likewise added to or removed from the publication. The CREATE PUBLICATION option publish_via_partition_root controls whether changes to partitions are published as their own changes or their parent's.
- Allow logical replication into partitioned tables on subscribers
- Previously, subscribers could only receive rows into non-partitioned tables
- Allow whole-row variables (that is, table.*) to be used in partitioning expressions
Indexes:
- More efficiently store duplicates in B-tree indexes
- This allows efficient B-tree indexing of low-cardinality columns by storing duplicate keys only once. Users upgrading with pg_upgrade will need to use REINDEX to make an existing index use this feature.
- Allow GiST and SP-GiST indexes on box columns to support ORDER BY box point queries
- Allow GIN indexes to more efficiently handle ! (NOT) clauses in tsquery searches
- Allow index operator classes to take parameters
- Allow CREATE INDEX to specify the GiST signature length and maximum number of integer ranges
- Indexes created on four and eight-byte integer array, tsvector, pg_trgm, ltree, and hstore columns can now control these GiST index parameters, rather than using the defaults.
- Prevent indexes that use non-default collations from being added as a table's unique or primary key constraint
- The index's collation must match that of the underlying column, but ALTER TABLE previously failed to check this.
Optimizer:
- Improve the optimizer's selectivity estimation for containment/match operators
- Allow setting the statistics target for extended statistics
- This is controlled with the new command option ALTER STATISTICS ... SET STATISTICS. Previously this was computed based on more general statistics target settings.
- Allow use of multiple extended statistics objects in a single query
- Allow use of extended statistics objects for OR clauses and IN/ANY constant lists
- Allow functions in FROM clauses to be pulled up (inlined) if they evaluate to constants
General Performance:
- Implement incremental sorting
- If an intermediate query result is known to be sorted by one or more leading keys of a required sort ordering, the additional sorting can be done considering only the remaining keys, if the rows are sorted in batches that have equal leading keys.
- If necessary, this can be controlled using enable_incremental_sort.
- Improve the performance of sorting inet values
- Allow hash aggregation to use disk storage for large aggregation result sets
- Previously, hash aggregation was avoided if it was expected to use more than work_mem memory. Now, a hash aggregation plan can be chosen despite that. The hash table will be spilled to disk if it exceeds work_mem times hash_mem_multiplier.
- This behavior is normally preferable to the old behavior, in which once hash aggregation had been chosen, the hash table would be kept in memory no matter how large it got — which could be very large if the planner had misestimated. If necessary, behavior similar to that can be obtained by increasing hash_mem_multiplier.
- Allow inserts, not only updates and deletes, to trigger vacuuming activity in autovacuum
- Previously, insert-only activity would trigger auto-analyze but not auto-vacuum, on the grounds that there could not be any dead tuples to remove. However, a vacuum scan has other useful side-effects such as setting page-all-visible bits, which improves the efficiency of index-only scans. Also, allowing an insert-only table to receive periodic vacuuming helps to spread out the work of “freezing” old tuples, so that there is not suddenly a large amount of freezing work to do when the entire table reaches the anti-wraparound threshold all at once.
- If necessary, this behavior can be adjusted with the new parameters autovacuum_vacuum_insert_threshold and autovacuum_vacuum_insert_scale_factor, or the equivalent table storage options.
- Add maintenance_io_concurrency parameter to control I/O concurrency for maintenance operations
- Allow WAL writes to be skipped during a transaction that creates or rewrites a relation, if wal_level is minimal
- Relations larger than wal_skip_threshold will have their files fsync'ed rather than generating WAL. Previously this was done only for COPY operations, but the implementation had a bug that could cause data loss during crash recovery.
- Improve performance when replaying DROP DATABASE commands when many tablespaces are in use
- Improve performance for truncation of very large relations
- Improve retrieval of the leading bytes of TOAST'ed values
- Previously, compressed out-of-line TOAST values were fully fetched even when it's known that only some leading bytes are needed. Now, only enough data to produce the result is fetched.
- Improve performance of LISTEN/NOTIFY
- Speed up conversions of integers to text
- Reduce memory usage for query strings and extension scripts that contain many SQL statements
Monitoring:
- Allow EXPLAIN, auto_explain, autovacuum, and pg_stat_statements to track WAL usage statistics
- Allow a sample of SQL statements, rather than all statements, to be logged
- A log_statement_sample_rate fraction of those statements taking more than log_min_duration_sample duration will be logged.
- Add the backend type to csvlog and optionally log_line_prefix log output
- Improve control of prepared statement parameter logging
- The GUC setting log_parameter_max_length controls the maximum length of parameter values output during logging of non-error statements, while log_parameter_max_length_on_error does the same for logging of statements with errors. Previously, prepared statement parameters were never logged during errors.
- Allow function call backtraces to be logged after errors
- The new parameter backtrace_functions specifies which C functions should generate backtraces on error.
- Make vacuum buffer counters 64-bits wide to avoid overflow
System Views:
- Add leader_pid to pg_stat_activity to report a parallel worker's leader process
- Add system view pg_stat_progress_basebackup to report the progress of streaming base backups
- Add system view pg_stat_progress_analyze to report ANALYZE progress
- Add system view pg_shmem_allocations to display shared memory usage
- Add system view pg_stat_slru to monitor internal SLRU caches
- Allow track_activity_query_size to be set as high as 1MB
- The previous maximum was 100kB
Wait Events:
- Report a wait event while creating a DSM segment with posix_fallocate()
- Add wait event VacuumDelay to report on cost-based vacuum delay
- Add wait events for WAL archive and recovery pause
- The new events are BackupWaitWalArchive and RecoveryPause
- Add wait events RecoveryConflictSnapshot and RecoveryConflictTablespace to monitor recovery conflicts
- Improve performance of wait events on BSD-based systems
- Authentication:
- Allow only superusers to view the ssl_passphrase_command setting
- This was changed as a security precaution.
- Change the server's default minimum TLS version for encrypted connections from 1.0 to 1.2
- This choice can be controlled by ssl_min_protocol_version
Server Configuration:
- Tighten rules on which utility commands are allowed in read-only transaction mode
- This change also increases the number of utility commands that can run in parallel queries
- Allow allow_system_table_mods to be changed after server start
- Disallow non-superusers from modifying system tables when allow_system_table_mods is set
- Previously, if allow_system_table_mods was set at server start, non-superusers could issue INSERT/UPDATE/DELETE commands on system tables
- Enable support for Unix-domain sockets on Windows
Streaming Replication and Recovery:
- Allow streaming replication configuration settings to be changed by reload
- Previously, a server restart was required to change primary_conninfo and primary_slot_name
- Allow WAL receivers to use a temporary replication slot when a permanent one is not specified
- This behavior can be enabled using wal_receiver_create_temp_slot
- Allow WAL storage for replication slots to be limited by max_slot_wal_keep_size
- Replication slots that would require exceeding this value are marked invalid
- Allow standby promotion to cancel any requested pause
- Previously, promotion could not happen while the standby was in paused state
- Generate an error if recovery does not reach the specified recovery target
- Previously, a standby would promote itself upon reaching the end of WAL, even if the target was not reached
- Allow control over how much memory is used by logical decoding before it is spilled to disk
- This is controlled by logical_decoding_work_mem
- Allow recovery to continue even if invalid pages are referenced by WAL
- This is enabled using ignore_invalid_pages
Utility Commands:
- Allow VACUUM to process a table's indexes in parallel
- The new PARALLEL option controls this
- Allow FETCH FIRST to use WITH TIES to return any additional rows that match the last result row
- Report planning-time buffer usage in EXPLAIN's BUFFER output
- Make CREATE TABLE LIKE propagate a CHECK constraint's NO INHERIT property to the created table
- When using LOCK TABLE on a partitioned table, do not check permissions on the child tables
- Allow OVERRIDING USER VALUE on inserts into identity columns
- Add ALTER TABLE ... DROP EXPRESSION to allow removing the GENERATED property from a column
- Fix bugs in multi-step ALTER TABLE commands
- IF NOT EXISTS clauses now work as expected, in that derived actions (such as index creation) do not execute if the column already exists. Also, certain cases of combining related actions into one ALTER TABLE now work when they did not before.
- Add ALTER VIEW syntax to rename view columns
- Renaming view columns was already possible, but one had to write ALTER TABLE RENAME COLUMN, which is confusing
- Add ALTER TYPE options to modify a base type's TOAST properties and support functions
- Add CREATE DATABASE LOCALE option
- This combines the existing options LC_COLLATE and LC_CTYPE into a single option
- Allow DROP DATABASE to disconnect sessions using the target database, allowing the drop to succeed
- This is enabled by the FORCE option
- Add structure member tg_updatedcols to allow C-language update triggers to know which column(s) were updated
Data Types:
- Add polymorphic data types for use by functions requiring compatible arguments
- The new data types are anycompatible, anycompatiblearray, anycompatiblenonarray, and anycompatiblerange
- Add SQL data type xid8 to expose FullTransactionId
- The existing xid data type is only four bytes so it does not provide the transaction epoch.
- Add data type regcollation and associated functions, to represent OIDs of collation objects
- Use the glibc version in some cases as a collation version identifier
- If the glibc version changes, a warning will be issued about possible corruption of collation-dependent indexes
- Add support for collation versions on Windows
- Allow ROW expressions to have their members extracted with suffix notation
- For example, (ROW(4, 5.0)).f1 now returns 4
Functions:
- Add alternate version of jsonb_set() with improved NULL handling
- The new function, jsonb_set_lax(), handles a NULL new value by either setting the specified key to a JSON null, deleting the key, raising an exception, or returning the jsonb value unmodified, as requested.
- Add jsonpath .datetime() method
- This function allows JSON values to be converted to timestamps, which can then be processed in jsonpath expressions. This change also adds jsonpath functions that support time-zone-aware output
- Add SQL functions NORMALIZE() to normalize Unicode strings, and IS NORMALIZED to check for normalization
- Add min() and max() aggregates for pg_lsn
- These are particularly useful in monitoring queries
- Allow Unicode escapes, e.g., E'unnnn' or U&'nnnn', to specify any character available in the database encoding, even when the database encoding is not UTF-8
- Allow to_date() and to_timestamp() to recognize non-English month/day names
- The names recognized are the same as those output by to_char() with the same format patterns
- Add datetime format patterns FF1 – FF6 to specify input or output of 1 to 6 fractional-second digits
- These patterns can be used by to_char(), to_timestamp(), and jsonpath's .datetime()
- Add SSSSS datetime format pattern as an SQL-standard alias for SSSS
- Add function gen_random_uuid() to generate version-4 UUIDs
- Previously UUID generation functions were only available in the external modules uuid-ossp and pgcrypto
- Add greatest-common-denominator (gcd) and least-common-multiple (lcm) functions
- Improve the performance and accuracy of the numeric type's square root (sqrt) and natural log (ln) functions
- Add function min_scale() that returns the number of digits to the right of the decimal point that are required to represent a numeric value with full accuracy
- Add function trim_scale() to reduce the scale of a numeric value by removing trailing zeros
- Add commutators of distance operators
- For example, previously only point line was supported, now line point works too
- Create xid8 versions of all transaction ID functions
- The old xid-based functions still exist, for backward compatibility
- Allow get_bit() and set_bit() to set bits beyond the first 256MB of a bytea value
- Allow advisory-lock functions to be used in some parallel operations
- Add the ability to remove an object's dependency on an extension
- The object can be a function, materialized view, index, or trigger. The syntax is ALTER .. NO DEPENDS ON
PL/pgSQL:
- Improve performance of simple PL/pgSQL expressions
- Improve performance of PL/pgSQL functions that use immutable expressions
Client Interfaces:
- Allow libpq clients to require channel binding for encrypted connections
- Using the libpq connection parameter channel_binding forces the other end of the TLS connection to prove it knows the user's password. This prevents man-in-the-middle attacks
- Add libpq connection parameters to control the minimum and maximum TLS version allowed for an encrypted connection
- The settings are ssl_min_protocol_version and ssl_max_protocol_version. By default, the minimum TLS version is 1.2 (this represents a behavioral change from previous releases)
- Allow use of passwords to unlock client certificates
- This is enabled by libpq's sslpassword connection parameter
- Allow libpq to use DER-encoded client certificates
- Fix ecpg's EXEC SQL elif directive to work correctly
- Previously it behaved the same as endif followed by ifdef, so that a successful previous branch of the same if construct did not prevent expansion of the elif branch or following branches
Client Applications:
psql:
- Add transaction status (%x) to psql's default prompts
- Allow the secondary psql prompt to be blank but the same width as the primary prompt
- This is accomplished by setting PROMPT2 to %w
- Allow psql's g and gx commands to change pset output options for the duration of that single command
- This feature allows syntax like g (expand=on), which is equivalent to gx
- Add psql commands to display operator classes and operator families
- The new commands are dAc, dAf, dAo, and dAp
- Show table persistence in psql's dt+ and related commands
- In verbose mode, the table/index/view shows if the object is permanent, temporary, or unlogged.
- Improve output of psql's d for TOAST tables
- Fix redisplay after psql's e command
- When exiting the editor, if the query doesn't end with a semicolon or g, the query buffer contents will now be displayed
- Add warn command to psql
- This is like echo except that the text is sent to stderr instead of stdout
- Add the PostgreSQL home page to command-line --help output
pgbench:
- Allow pgbench to partition its “accounts” table
- This allows performance testing of partitioning
- Add pgbench command aset, which behaves like gset, but for multiple queries
- Allow pgbench to generate its initial data server-side, rather than client-side
- Allow pgbench to show script contents using option --show-script
Server Applications:
- Generate backup manifests for base backups, and verify them
- A new tool pg_verifybackup can verify backups
- Have pg_basebackup estimate the total backup size by default
- This computation allows pg_stat_progress_basebackup to show progress. If that is not needed, it can be disabled by using the --no-estimate-size option. Previously, this computation happened only if the --progress option was used.
- Add an option to pg_rewind to configure standbys
- This matches pg_basebackup's --write-recovery-conf option
- Allow pg_rewind to use the target cluster's restore_command to retrieve needed WAL
- This is enabled using the -c/--restore-target-wal option
- Have pg_rewind automatically run crash recovery before rewinding
- This can be disabled by using --no-ensure-shutdown
- Increase the PREPARE TRANSACTION-related information reported by pg_waldump
- Add pg_waldump option --quiet to suppress non-error output
- Add pg_dump option --include-foreign-data to dump data from foreign servers
- Allow vacuum commands run by vacuumdb to operate in parallel mode
- This is enabled with the new --parallel option
- Allow reindexdb to operate in parallel
- Parallel mode is enabled with the new --jobs option
- Allow dropdb to disconnect sessions using the target database, allowing the drop to succeed
- This is enabled with the -f option
- Remove --adduser and --no-adduser from createuser
- The long-supported preferred options for this are called --superuser and --no-superuser
- Use the directory of the pg_upgrade program as the default --new-bindir setting when running pg_upgrade
Documentation:
- Add a glossary to the documentation
- Reformat tables containing function and operator information for better clarity
- Upgrade to use DocBook 4.5
Source Code:
- Add support for building on Visual Studio 2019
- Add build support for MSYS2
- Add compare_exchange and fetch_add assembly language code for Power PC compilers
- Update Snowball stemmer dictionaries used by full text search
- This adds Greek stemming and improves Danish and French stemming
- Remove support for Windows 2000
- Remove support for non-ELF BSD systems
- Remove support for Python versions 2.5.X and earlier
- Remove support for OpenSSL 0.9.8 and 1.0.0
- Remove configure options --disable-float8-byval and --disable-float4-byval
- These were needed for compatibility with some version-zero C functions, but those are no longer supported
- Pass the query string to planner hook functions
- Add TRUNCATE command hook
- Add TLS init hook
- Allow building with no predefined Unix-domain socket directory
- Reduce the probability of SysV resource key collision on Unix platforms
- Use operating system functions to reliably erase memory that contains sensitive information
- For example, this is used for clearing passwords stored in memory
- Add headerscheck script to test C header-file compatibility
- Implement internal lists as arrays, rather than a chain of cells
- This improves performance for queries that access many objects
- Change the API for TS_execute()
- TS_execute callbacks must now provide ternary (yes/no/maybe) logic. Calculating NOT queries accurately is now the default
Additional Modules:
- Allow extensions to be specified as trusted
- Such extensions can be installed in a database by users with database-level CREATE privileges, even if they are not superusers. This change also removes the pg_pltemplate system catalog
- Allow non-superusers to connect to postgres_fdw foreign servers without using a password
- Specifically, allow a superuser to set password_required to false for a user mapping. Care must still be taken to prevent non-superusers from using superuser credentials to connect to the foreign server.
- Allow postgres_fdw to use certificate authentication
- Different users can use different certificates
- Allow sepgsql to control access to the TRUNCATE command
- Add extension bool_plperl which transforms SQL booleans to/from PL/Perl booleans
- Have pg_stat_statements treat SELECT ... FOR UPDATE commands as distinct from those without FOR UPDATE
- Allow pg_stat_statements to optionally track the planning time of statements
- Previously only execution time was tracked
- Overhaul ltree's lquery syntax to treat NOT (!) more logically
- Also allow non-* queries to use a numeric range ({}) of matches
- Add support for binary I/O of ltree, lquery, and ltxtquery types
- Add an option to dict_int to ignore the sign of integers
- Add adminpack function pg_file_sync() to allow fsync'ing a file
- Add pageinspect functions to output t_infomask/t_infomask2 values in human-readable format
- Add B-tree index de-duplication processing columns to pageinspect output
 OperaOpera 117.0 Build 5408.197 (64-bit)
OperaOpera 117.0 Build 5408.197 (64-bit) PC RepairPC Repair Tool 2025
PC RepairPC Repair Tool 2025 PhotoshopAdobe Photoshop CC 2025 26.5.0 (64-bit)
PhotoshopAdobe Photoshop CC 2025 26.5.0 (64-bit) OKXOKX - Buy Bitcoin or Ethereum
OKXOKX - Buy Bitcoin or Ethereum iTop VPNiTop VPN 6.3.0 - Fast, Safe & Secure
iTop VPNiTop VPN 6.3.0 - Fast, Safe & Secure Premiere ProAdobe Premiere Pro CC 2025 25.2
Premiere ProAdobe Premiere Pro CC 2025 25.2 BlueStacksBlueStacks 10.42.50.1004
BlueStacksBlueStacks 10.42.50.1004 Hero WarsHero Wars - Online Action Game
Hero WarsHero Wars - Online Action Game SemrushSemrush - Keyword Research Tool
SemrushSemrush - Keyword Research Tool LockWiperiMyFone LockWiper (Android) 5.7.2
LockWiperiMyFone LockWiper (Android) 5.7.2
Comments and User Reviews