-
Latest Version
-
Operating System
Windows XP64 / Vista64 / Windows 7 64 / Windows 8 64 / Windows 10 64
-
User Rating
Click to vote -
Author / Product
-
Filename
postgresql-11.9-1-windows-x64.exe
Sometimes latest versions of the software can cause issues when installed on older devices or devices running an older version of the operating system.
Software makers usually fix these issues but it can take them some time. What you can do in the meantime is to download and install an older version of PostgreSQL 11.9.
For those interested in downloading the most recent release of PostgreSQL or reading our review, simply click here.
All old versions distributed on our website are completely virus-free and available for download at no cost.
We would love to hear from you
If you have any questions or ideas that you want to share with us - head over to our Contact page and let us know. We value your feedback!
-
PostgreSQL 11.9 Screenshots
The images below have been resized. Click on them to view the screenshots in full size.
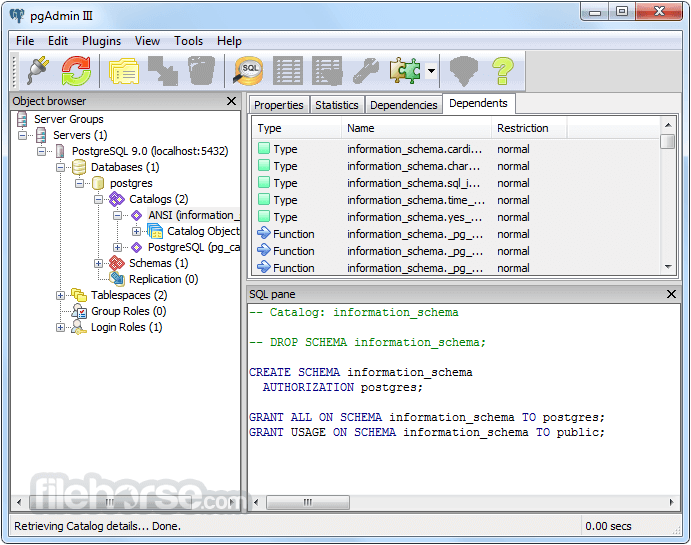
-
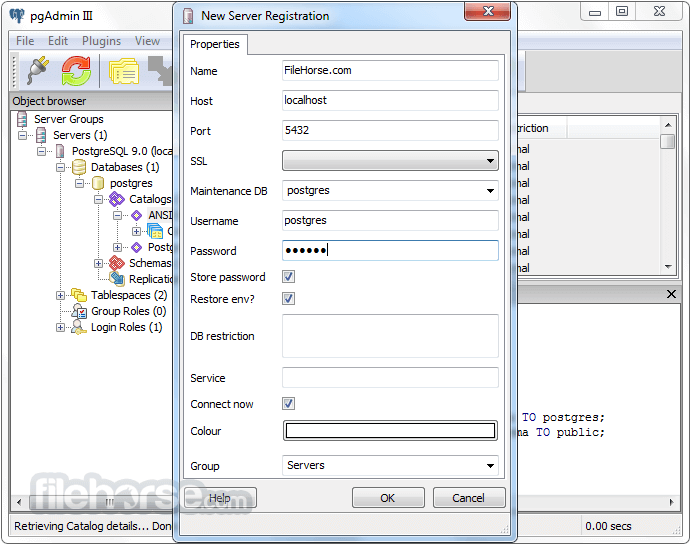
-
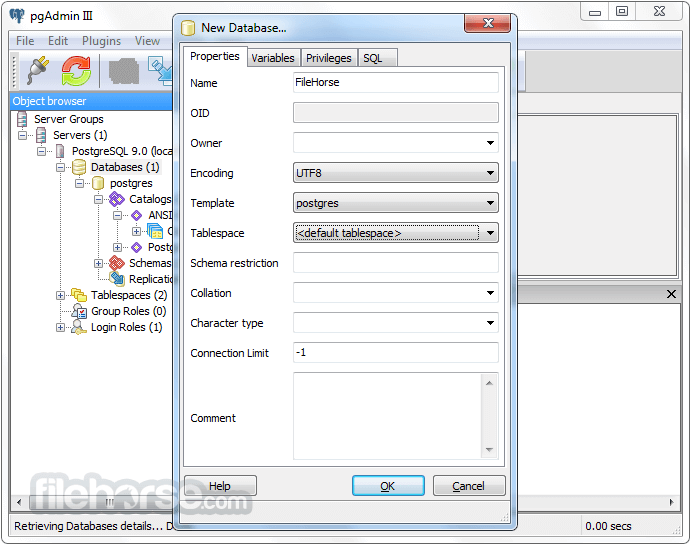
-

-

What's new in this version:
- Set a secure search_path in logical replication walsenders and apply workers (Noah Misch)
- A malicious user of either the publisher or subscriber database could potentially cause execution of arbitrary SQL code by the role running replication, which is often a superuser. Some of the risks here are equivalent to those described in CVE-2018-1058, and are mitigated in this patch by ensuring that the replication sender and receiver execute with empty search_path settings. (As with CVE-2018-1058, that change might cause problems for under-qualified names used in replicated tables' DDL.) Other risks are inherent in replicating objects that belong to untrusted roles; the most we can do is document that there is a hazard to consider. (CVE-2020-14349)
- Make contrib modules' installation scripts more secure (Tom Lane)
- Attacks similar to those described in CVE-2018-1058 could be carried out against an extension installation script, if the attacker can create objects in either the extension's target schema or the schema of some prerequisite extension. Since extensions often require superuser privilege to install, this can open a path to obtaining superuser privilege. To mitigate this risk, be more careful about the search_path used to run an installation script; disable check_function_bodies within the script; and fix catalog-adjustment queries used in some contrib modules to ensure they are secure. Also provide documentation to help third-party extension authors make their installation scripts secure. This is not a complete solution; extensions that depend on other extensions can still be at risk if installed carelessly. (CVE-2020-14350)
- Fix edge cases in partition pruning (Etsuro Fujita, Dmitry Dolgov)
- When there are multiple partition key columns, generation of pruning tests could misbehave if some columns had no constraining WHERE clauses or multiple constraining clauses. This could lead to server crashes, incorrect query results, or assertion failures.
- Fix construction of parameterized BitmapAnd and BitmapOr index scans on the inside of partition-wise nestloop joins (Tom Lane)
- A plan in which such a scan needed to use a value from the outside of the join would usually crash at execution.
- In logical replication walsender, fix failure to send feedback messages after sending a keepalive message (Álvaro Herrera)
- This is a relatively minor problem when using built-in logical replication, because the built-in walreceiver will send a feedback reply (which clears the incorrect state) fairly frequently anyway. But with some other replication systems, such as pglogical, it causes significant performance issues.
- Fix firing of column-specific UPDATE triggers in logical replication subscribers (Tom Lane)
- The code neglected to account for the possibility of column numbers being different between the publisher and subscriber tables, so that if those were indeed different, wrong decisions might be made about which triggers to fire.
- Update oldest xmin and LSN values during pg_replication_slot_advance() (Michael Paquier)
- This function previously failed to do that, possibly preventing resource cleanup (such as removal of no-longer-needed WAL segments) after manual advancement of a replication slot.
- Fix slow execution of ts_headline() (Tom Lane)
- The phrase-search fix added in our previous set of minor releases could cause ts_headline() to take unreasonable amounts of time for long documents; to make matters worse, the query was not cancellable within the troublesome loop.
- Ensure the repeat() function can be interrupted by query cancel (Joe Conway)
- Fix pg_current_logfile() to not include a carriage return (r) in its result on Windows (Tom Lane)
- Ensure that pg_read_file() and related functions read until EOF is reached (Joe Conway)
- Previously, if not given a specific data length to read, these functions would stop at whatever file length was reported by stat(). That's unhelpful for pipes and other sorts of virtual files.
- Fix mis-handling of NaN inputs during parallel aggregation on numeric-type columns (Tom Lane)
- If some partial aggregation workers found only NaNs while others found only non-NaNs, the results were combined incorrectly, possibly leading to the wrong overall result (i.e., not NaN when it should be).
- Reject time-of-day values greater than 24 hours (Tom Lane)
- The intention of the datetime input code is to allow “24:00:00” or equivalently “23:59:60”, but no larger value. However, the range check was miscoded so that it would accept “23:59:60.nnn” with nonzero fractional-second nnn. In timestamp values this would result in wrapping into the first second of the next day. In time and timetz values, the stored value would actually be more than 24 hours, causing dump/reload failures and possibly other misbehavior.
- Undo double-quoting of index names in EXPLAIN's non-text output formats (Tom Lane, Euler Taveira)
- Fix EXPLAIN's accounting for resource usage, particularly buffer accesses, in parallel workers in a plan using Gather Merge nodes (Jehan-Guillaume de Rorthais)
- Fix timing of constraint revalidation in ALTER TABLE (David Rowley)
- If ALTER TABLE needs to fully rewrite the table's contents (for example, due to change of a column's data type) and also needs to scan the table to re-validate foreign keys or CHECK constraints, it sometimes did things in the wrong order, leading to odd errors such as “could not read block 0 in file "base/nnnnn/nnnnn": read only 0 of 8192 bytes”.
- Work around incorrect not-null markings for pg_subscription.subslotname and pg_subscription_rel.srsublsn (Tom Lane)
- The bootstrap catalog data incorrectly marks these two catalog columns as always non-null. There's no easy way to correct that mistake in existing installations (though v13 and later will have the correct markings). The main place that depends on that marking being correct is JIT-enabled tuple deconstruction, so teach it to explicitly ignore the marking for these two columns. Also adjust some C code that accessed srsublsn without checking to see if it's null; a crash from that is improbable but perhaps not impossible.
- Cope with LATERAL references in restriction clauses attached to an un-flattened sub-SELECT in the FROM clause (Tom Lane)
- This oversight could result in assertion failures or crashes at query execution.
- Avoid believing that a never-analyzed foreign table has zero tuples (Tom Lane)
- This primarily affected the planner's estimate of the number of groups that would be obtained by GROUP BY.
- Remove bogus warning about “leftover placeholder tuple” in BRIN index de-summarization (Álvaro Herrera)
- The case can occur legitimately after a cancelled vacuum, so warning about it is overly noisy.
- Fix selection of tablespaces for “shared fileset” temporary files (Magnus Hagander, Tom Lane)
- If temp_tablespaces is empty or explicitly names the database's primary tablespace, such files got placed into the pg_default tablespace rather than the database's primary tablespace as expected.
- Fix corner-case error in masking of SP-GiST index pages during WAL consistency checking (Alexander Korotkov)
- This could cause false failure reports when wal_consistency_checking is enabled.
- Improve error handling in the server's buffile module (Thomas Munro)
- Fix some cases where I/O errors were indistinguishable from reaching EOF, or were not reported at all. Also add details such as block numbers and byte counts where appropriate.
- Fix conflict-checking anomalies in SERIALIZABLE isolation mode (Peter Geoghegan)
- If a concurrently-inserted tuple was updated by a different concurrent transaction, and neither tuple version was visible to the current transaction's snapshot, serialization conflict checking could draw the wrong conclusions about whether the tuple was relevant to the results of the current transaction. This could allow a serializable transaction to commit when it should have failed with a serialization error.
- Avoid repeated marking of dead btree index entries as dead (Masahiko Sawada)
- While functionally harmless, this led to useless WAL traffic when checksums are enabled or wal_log_hints is on.
- Avoid trouble during cleanup of a non-exclusive backup when JIT compilation has been activated during the backup (Robert Haas)
- Fix failure of some code paths to acquire the correct lock before modifying pg_control (Nathan Bossart, Fujii Masao)
- This oversight could allow pg_control to be written out with an inconsistent checksum, possibly causing trouble later, including inability to restart the database if it crashed before the next pg_control update.
- Fix errors in currtid() and currtid2() (Michael Paquier)
- These functions (which are undocumented and used only by ancient versions of the ODBC driver) contained coding errors that could result in crashes, or in confusing error messages such as “could not open file” when applied to a relation having no storage.
- Avoid calling elog() or palloc() while holding a spinlock (Michael Paquier, Tom Lane)
- Logic associated with replication slots had several violations of this coding rule. While the odds of trouble are quite low, an error in the called function would lead to a stuck spinlock.
- Fix assertion in logical replication subscriber to allow use of REPLICA IDENTITY FULL (Euler Taveira)
- This was just an incorrect assertion, so it has no impact on standard production builds.
- Report out-of-disk-space errors properly in pg_dump and pg_basebackup (Justin Pryzby, Tom Lane, Álvaro Herrera)
- Some code paths could produce silly reports like “could not write file: Success”.
- Fix parallel restore of tables having both table-level privileges and per-column privileges (Tom Lane)
- The table-level privilege grants have to be applied first, but a parallel restore did not reliably order them that way; this could lead to “tuple concurrently updated” errors, or to disappearance of some per-column privilege grants. The fix for this is to include dependency links between such entries in the archive file, meaning that a new dump has to be taken with a corrected pg_dump to ensure that the problem will not recur.
- Ensure that pg_upgrade runs with vacuum_defer_cleanup_age set to zero in the target cluster (Bruce Momjian)
- If the target cluster's configuration has been modified to set vacuum_defer_cleanup_age to a nonzero value, that prevented freezing of the system catalogs from working properly, which caused the upgrade to fail in confusing ways. Ensure that any such setting is overridden for the duration of the upgrade.
- Fix pg_recvlogical to drain pending messages before exiting (Noah Misch)
- Without this, the replication sender might detect a send failure and exit without making the expected final update to the replication slot's LSN position. That led to re-transmitting data after the next connection. It was also possible to miss error messages sent after the last data that pg_recvlogical wants to consume.
- Fix pg_rewind's handling of just-deleted files in the source data directory (Justin Pryzby, Michael Paquier)
- When working with an on-line source database, concurrent file deletions are possible, but pg_rewind would get confused if deletion happened between seeing a file's directory entry and examining it with stat().
- Make pg_test_fsync use binary I/O mode on Windows (Michael Paquier)
- Previously it wrote the test file in text mode, which is not an accurate reflection of PostgreSQL's actual usage.
- Fix contrib/amcheck to not complain about deleted index pages that are empty (Alexander Korotkov)
- This state of affairs is normal during WAL replay.
- Fix failure to initialize local state correctly in contrib/dblink (Joe Conway)
- With the right combination of circumstances, this could lead to dblink_close() issuing an unexpected remote COMMIT.
- Fix contrib/pgcrypto's misuse of deflate() (Tom Lane)
- The pgp_sym_encrypt functions could produce incorrect compressed data due to mishandling of zlib's API requirements. We have no reports of this error manifesting with stock zlib, but it can be seen when using IBM's zlibNX implementation.
- Fix corner case in decompression logic in contrib/pgcrypto's pgp_sym_decrypt functions (Kyotaro Horiguchi, Michael Paquier)
- A compressed stream can validly end with an empty packet, but the decompressor failed to handle this and would complain about corrupt data.
- Use POSIX-standard strsignal() in place of the BSD-ish sys_siglist[] (Tom Lane)
- This avoids build failures with very recent versions of glibc.
- Support building our NLS code with Microsoft Visual Studio 2015 or later (Juan José Santamaría Flecha, Davinder Singh, Amit Kapila)
- Avoid possible failure of our MSVC install script when there is a file named configure several levels above the source code tree (Arnold Müller)
- This could confuse some logic that looked for configure to identify the top level of the source tree.
 OperaOpera 125.0 Build 5729.21 (64-bit)
OperaOpera 125.0 Build 5729.21 (64-bit) MalwarebytesMalwarebytes Premium 5.4.5
MalwarebytesMalwarebytes Premium 5.4.5 PhotoshopAdobe Photoshop CC 2026 27.1 (64-bit)
PhotoshopAdobe Photoshop CC 2026 27.1 (64-bit) BlueStacksBlueStacks 10.42.153.1001
BlueStacksBlueStacks 10.42.153.1001 OKXOKX - Buy Bitcoin or Ethereum
OKXOKX - Buy Bitcoin or Ethereum Premiere ProAdobe Premiere Pro CC 2025 25.6.3
Premiere ProAdobe Premiere Pro CC 2025 25.6.3 PC RepairPC Repair Tool 2025
PC RepairPC Repair Tool 2025 Hero WarsHero Wars - Online Action Game
Hero WarsHero Wars - Online Action Game TradingViewTradingView - Trusted by 60 Million Traders
TradingViewTradingView - Trusted by 60 Million Traders Edraw AIEdraw AI - AI-Powered Visual Collaboration
Edraw AIEdraw AI - AI-Powered Visual Collaboration
Comments and User Reviews