-
Latest Version
MySQL Workbench 8.0.47 LATEST
-
Review by
-
Operating System
Windows 10 (64-bit) / Windows 11
-
User Rating
Click to vote -
Author / Product
-
Filename
mysql-workbench-community-8.0.47-winx64.msi
Developed by Oracle, it provides database administrators, developers, and data architects with a unified visual platform to design, develop, and manage MySQL databases.
MySQL Workbench Desktop for Windows is available in both Community (FREE) and Commercial editions, offering a range of features for database modeling, SQL development, administration, and performance tuning.
Key Features
Database Modeling and Design – Allows users to create and modify ER diagrams, forward and reverse engineer schemas, and visually design database structures.
SQL Development – Offers an SQL editor with syntax highlighting, auto-completion, and query execution tools.
Database Administration – Provides features for managing users, privileges, server configuration, logs, and backup management.
Performance Monitoring and Tuning – Includes built-in tools for database performance analysis, query optimization, and debugging.
Data Migration – Supports migration from various databases such as Microsoft SQL Server, PostgreSQL, and SQLite to MySQL.
User Interface
The interface of MySQL Workbench is clean and well-organized, with three main panels:
Navigator Panel – Lists database objects such as schemas, tables, and views.
SQL Editor Panel – Allows users to write and execute SQL queries with syntax highlighting and auto-completion.
Results Grid – Displays query execution results in a tabular format, with export options for reports.
While the UI is feature-rich, beginners might find it overwhelming due to its complexity.
Installation and Setup
- Download the App – Available from the official MySQL website or FileHorse.
- Install MySQL Server – Required for Workbench to function properly.
- Run the Installer – Select the appropriate version and configure MySQL connections.
- Connect to a Database – Use the MySQL Workbench connection manager to connect to a local or remote MySQL server.
- Start Using MySQL Workbench – Create schemas, execute queries, or manage databases.
Creating a New Database – Open MySQL Workbench, go to “Schemas” and click on “Create Schema.”
Writing SQL Queries – Use the SQL editor to write and execute queries.
Designing Database Models – Use the model editor to create ER diagrams and generate SQL scripts.
Performing Data Migration – Access the data migration wizard to transfer data from other database platforms.
Managing Users and Privileges – Navigate to the “Administration” tab to set user roles and permissions.
FAQ
Is MySQL Workbench free to use?
Yes, the Community Edition is free, but there are Commercial editions with additional features.
Can MySQL Workbench connect to remote databases?
Yes, it supports SSH tunneling and direct remote connections.
Does MySQL Workbench support other databases besides MySQL?
It is primarily designed for MySQL but supports migration from other database systems.
How do I optimize query performance in MySQL Workbench?
Use the Query Analyzer and Performance Schema tools to analyze and optimize queries.
Is MySQL Workbench available for macOS and Linux?
Yes, it is cross-platform and available for Windows, macOS, and Linux.
Alternatives
DBeaver – Open-source multi-database management tool with a modern interface.
HeidiSQL – Lightweight MySQL administration tool with a focus on speed and simplicity.
phpMyAdmin – Web-based MySQL management tool with an intuitive UI.
Navicat for MySQL – Premium database management tool with advanced features.
TablePlus – Modern GUI tool for multiple database engines including MySQL.
Pricing
MySQL Workbench Community Edition – Free
MySQL Workbench Commercial Edition – Part of MySQL Enterprise subscription (pricing varies)
System Requirements
- OS: Windows 11 or Windows 10 (64-bit)
- Processor: Intel or AMD 64-bit processor
- RAM: Minimum 4GB (8GB+ recommended)
- Storage: At least 200MB free disk space
- Graphics: DirectX 10 compatible graphics card
- Comprehensive set of tools for MySQL database management
- Supports database design, SQL development, and administration
- Free Community Edition available with essential features
- Built-in performance monitoring and optimization tools
- Data migration tools for transferring from other databases
- Can be resource-intensive for large databases
- Limited support for non-MySQL databases
- UI can be overwhelming due to feature complexity
- Some advanced features are locked behind a paid subscription
MySQL Workbench is a must-have tool for MySQL developers and administrators who need a robust and feature-rich database management environment. While it offers powerful tools for database design, SQL execution, and performance tuning, beginners may find its interface and functionality challenging at first.
Note: Requires .NET Framework.
Also Available: Download MySQL Workbench for Mac
-
MySQL Workbench 8.0.47 Screenshots
The images below have been resized. Click on them to view the screenshots in full size.
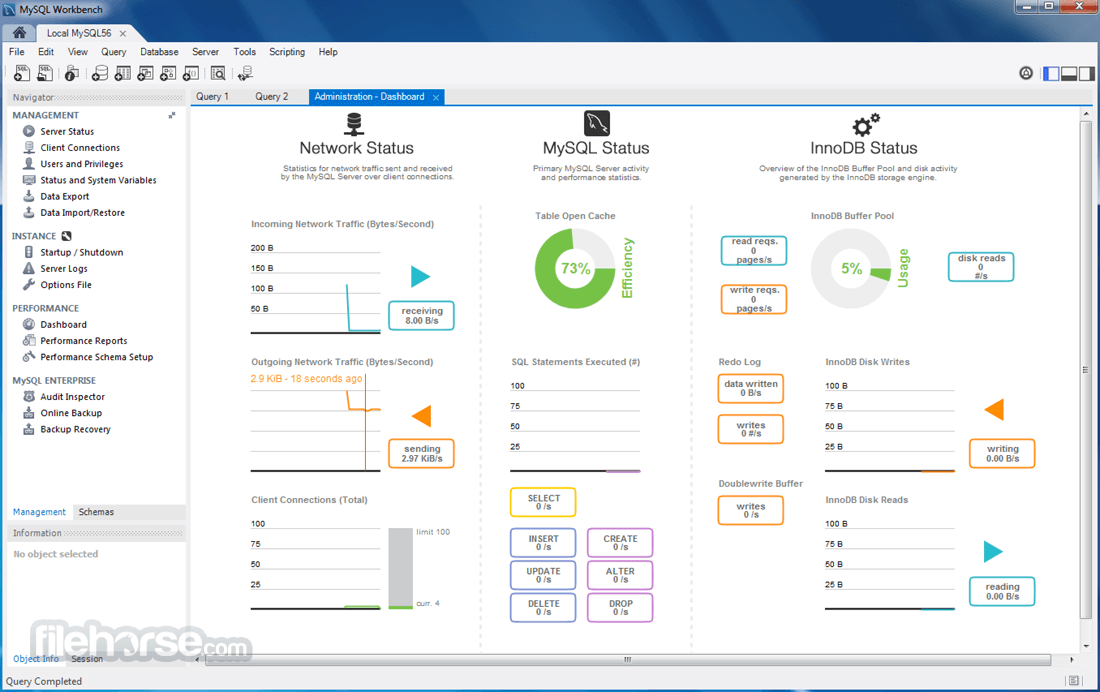
What's new in this version:
Functionality Added or Changed:
- MySQL HeatWave Migration Assistant now supports partial migrations, allowing users to choose what schemas and objects to migrate, including individual DB objects such as schemas, tables, views, routines, events, triggers, libraries, and user accounts
- For more information, see MySQL HeatWave Migration Assistant
- MySQL HeatWave Migration Assistant now attempts to connect to the source instance from the jump host in OCI. If the connection is successful, data will be transferred from the jump host instead of the host where the migration assistant is running.
 OperaOpera 131.0 Build 5877.55 (64-bit)
OperaOpera 131.0 Build 5877.55 (64-bit) AdsPowerAdsPower - Antidetect Browser
AdsPowerAdsPower - Antidetect Browser PhotoshopAdobe Photoshop CC 2026 27.5 (64-bit)
PhotoshopAdobe Photoshop CC 2026 27.5 (64-bit) BlueStacks AIBlueStacks AI
BlueStacks AIBlueStacks AI OKXOKX - Buy Bitcoin or Ethereum
OKXOKX - Buy Bitcoin or Ethereum CapCutCapCut 8.5.0
CapCutCapCut 8.5.0 PC RepairPC Repair Tool 2026
PC RepairPC Repair Tool 2026 Hero WarsHero Wars - Online Action Game
Hero WarsHero Wars - Online Action Game TradingViewTradingView - Trusted by 100 Million Traders
TradingViewTradingView - Trusted by 100 Million Traders AdGuard VPNAdGuard VPN 2.9.0
AdGuard VPNAdGuard VPN 2.9.0
Comments and User Reviews