-
Latest Version
Cyotek WebCopy 1.9.1 Build 872 LATEST
-
Review by
-
Operating System
Windows Vista / Windows 7 / Windows 8 / Windows 10
-
User Rating
Click to vote -
Author / Product
-
Filename
setup-cyowcopy-1.9.1.872-x86.exe
-
MD5 Checksum
a140259ec36b24ed0e514e9c23f08ded
Developed by Cyotek, this software scans a website’s content and resources, copying all linked resources such as images, stylesheets, and pages while maintaining the internal structure of the site.
WebCopy is particularly useful for users who need to archive websites, analyze their structure, or access content without an internet connection.
This lightweight yet feature-rich tool is popular among web developers, researchers, and those who frequently work in offline environments.
Main Features
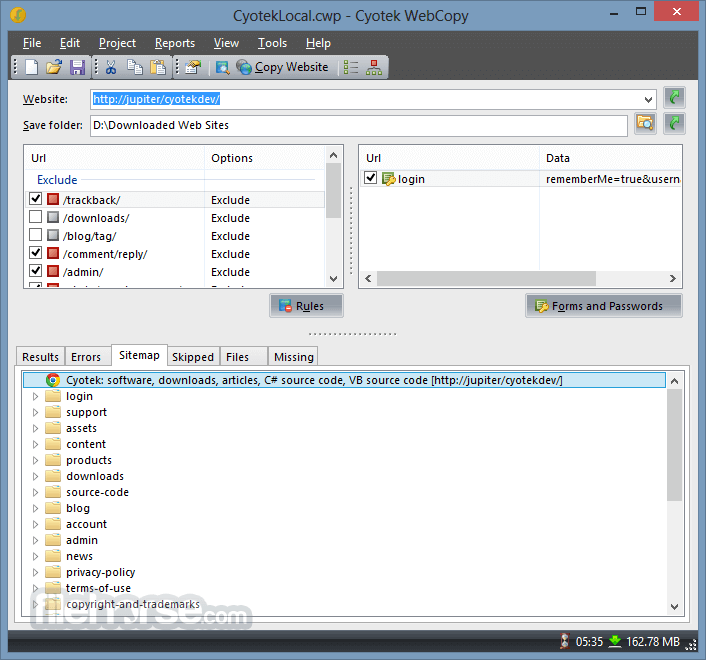
- Website Crawling and Copying: WebCopy’s primary feature is its ability to crawl through a website and download its pages, linked resources, and assets. It preserves the website’s directory structure, allowing for an accurate offline browsing experience.
- Customizable Download Rules: Users can set specific rules to include or exclude certain parts of a website. For instance, you can configure this app to download only specific file types (e.g., HTML pages, images, or PDFs).
- Authentication Support: For websites that require authentication, it can be configured to provide the necessary login credentials, allowing users to copy secured areas of a site.
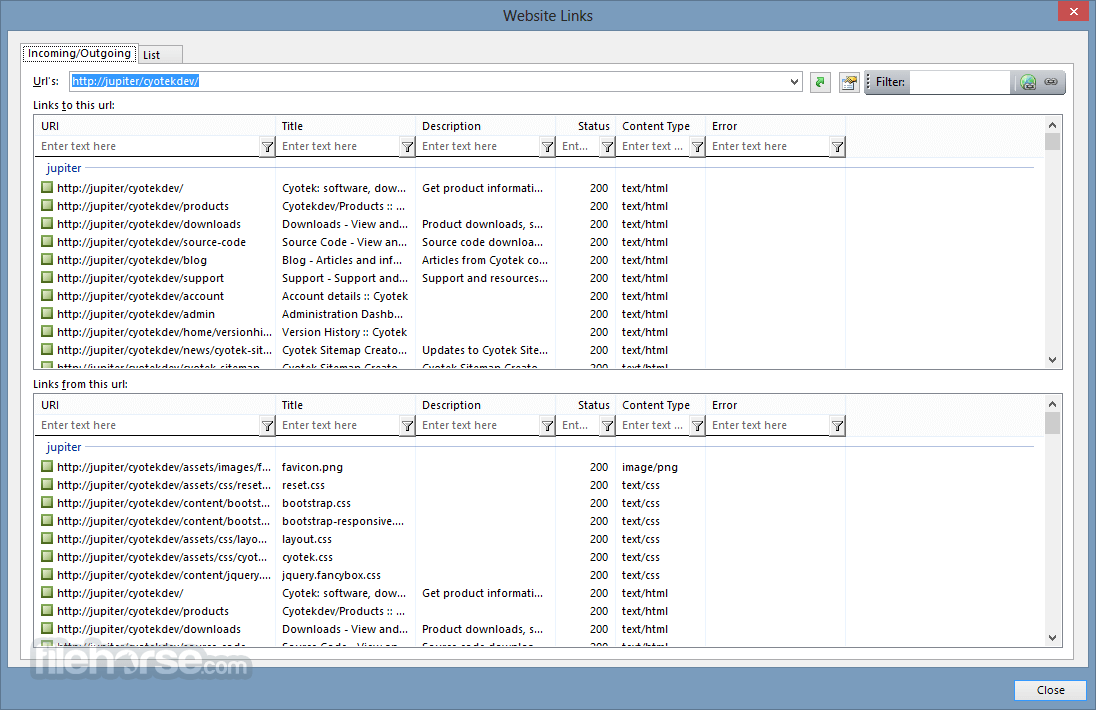
- Sitemap and Link Map Generation: It can generate a visual sitemap of a website, making it easier for users to understand its structure and navigate its content.
- Error Reporting and Logs: The software provides detailed logs of the copy process, including error reports on inaccessible resources or links, helping users identify potential issues on the original website.
It features a clean, straightforward interface, ideal for both beginners and advanced users. The main dashboard provides easy access to essential functions, such as project creation, download rules, and detailed reports. Key areas of the interface include:
Project Manager: The project manager allows users to save multiple configurations for different websites, making it easy to revisit and manage previous downloads.
Rules Panel: The rules panel is where users can define inclusion and exclusion filters for file types, folders, or specific URLs.
Status Bar: This shows the progress of the website copying process, with real-time updates on the number of downloaded files and current operation.
The interface is intuitive, but may feel a bit dated compared to modern software designs. However, its simplicity makes it highly functional and accessible to users of all experience levels.
Installation and Setup
- Download the Installer: The software can be downloaded from Cyotek’s official website or FileHorse.
- Run the Installer: Once the installer is launched, follow the on-screen prompts to complete the installation process.
- Launch and Configure: After installation, open the software and configure your first project by specifying the URL of the website you wish to copy.
- Define Rules: Set the inclusion and exclusion rules for the content you want to copy.
- Start Copying: Click the "Copy" button to begin downloading the website. You can monitor the progress through the status bar and logs.
How to Use
Create a New Project: Open the software, click "New Project," and enter the URL of the website you want to copy.
Set Download Rules: Navigate to the "Rules" section to define which file types or directories should be included or excluded. This is important for controlling the scope of your download.

Authentication Settings (If Needed): If the website requires login credentials, input them under the "Authentication" tab.
Start the Copy Process: After setting up your project, click "Copy" to begin downloading the website’s resources. You can track the progress and check the status for any errors or skipped files.
View Offline Content: Once the process is complete, you can open the copied website from the specified local folder and view it offline.
FAQ
Can WebCopy handle dynamic content such as JavaScript-heavy websites?
The tool primarily deals with static content. Websites with heavy reliance on JavaScript for loading content may not be fully copied or rendered offline.
Can I copy only a part of a website instead of the entire site?
Yes, you can specify download rules to target only specific parts of a website, such as certain file types or directories.
Does Cyotek WebCopy work with websites that require login?
Yes, it supports basic authentication and allows users to input credentials for sites that require login.
What happens if a link or resource is unavailable during the copy process?
It will log any errors or missing resources, and these will appear in the report. It will continue the copy process and skip the unavailable files.
Can WebCopy be used to copy password-protected websites?
Yes, but only if you have legitimate access to the website and provide the necessary credentials.
What is WebCopy capable of?
It analyzes a website's HTML structure and attempts to identify all linked resources such as pages, images, videos, and file downloads. It then downloads these resources and continues searching for more, enabling it to "crawl" an entire website. By doing this, it aims to replicate the content and structure of the original site as closely as possible.
What limitations does WebCopy have?
This tool does not include a virtual DOM or JavaScript parsing capabilities. Websites that rely heavily on JavaScript for functionality may pose challenges for this app, as it may not be able to accurately replicate the site if JavaScript dynamically generates links or content.
Additionally, WebCopy doesn't download the raw source code of a website but instead retrieves what is provided by the HTTP server. This means that while it attempts to create an offline version of a site, complex data-driven websites may not function as expected once copied.

Alternatives
HTTrack: A popular open-source alternative, HTTrack also allows users to download websites for offline browsing.
Pricing
The program is free software available for personal and commercial use.
There are no hidden fees or premium features locked behind a paywall, making it an attractive option for users who need website copying functionality without financial commitment.
System Requirements
- Operating System: Windows 7, 8, 10, 11 (32-bit and 64-bit)
- Processor: 1 GHz or faster
- Memory: 512 MB of RAM
- Storage: Around 20 MB of available space
- Free to use
- Simple and customizable rules for downloading websites
- Supports basic authentication
- Easy-to-use interface
- Lack of official support and updates
- May struggle with dynamic, JavaScript-heavy websites
- Limited advanced features compared to some paid alternatives
Cyotek WebCopy is an effective tool for those looking to download static websites for offline viewing or analysis. Its simplicity, ease of use, and customization options make it suitable for both casual users and professionals.
While it may lack advanced features for handling dynamic content, its free price tag and reliable performance for static websites make it a worthy choice in the realm of website copiers. If you need more advanced functionality or dynamic content handling, alternatives like HTTrack or Offline Explorer may be better suited to your needs.
Note: Requires .NET Framework.
-
Cyotek WebCopy 1.9.1 Build 872 Screenshots
The images below have been resized. Click on them to view the screenshots in full size.
-
-
-
-

What's new in this version:
Added:
- Added the ability to read cookies from an external file
- Added the ability to read cookies from an external file
- Test URL dialogue now allows configuring cookies
- Added cookie, cookie-jar and discard-session-cookies command line parameters (User Manual)
- Added support for the legacy compress
Changed:
- Documentation improvements
- Test URL dialogue now uses load on demand for settings pages
- 401 challenges no longer display credential dialogues unless the authentication type is either Basic or Digest as no other values have been tested due to lack of resource
- Updated mime database
Fixed:
- Posting a form did not set an appropriate content type
- Custom headers were not applied when posting forms
- If a URL was previously skipped but then included in future scans, the original skip reason could be retained
- A blank error message was displayed for Brotli decompression errors
- One-time project validation checks were ignoring the content encoding settings of the project (which by default is Gzip and Deflate) and were requesting content with Brotli compression
- Brotli decompression could fail with streams larger than 65535 bytes
- The URI transformation service incorrectly attempted to add prefixes to email addresses, this in turn caused a crash if the mailto: reference was malformed
- A crash could occur if a content type header was malformed and was either utf or utf-
- Fixed an issue where command line arguments sometimes didn't correctly process ambiguous relative arguments that could be a file name or a unqualified URI
- Fixed a crash that could occur when switching between empty virtual list views during a crawl and items were then subsequently added
- A crash which could occur when loading localised text is no longer fatal
- Speed and estimated downtime time calculations were incorrect and could cause a crash when downloading large files
- A crash would occur when editing a file that didn't have a mime type
- Speculative fix for a crash that could occur when finishing the New Project Wizard
- Fixed a crash that occurred if a 401 challenge was received and the www-authenticate header was a bare type
- If a website returns a non-standard Content-Encoding value (or one currently not supported by WebCopy), no attempt will be made to decompress the file and it will be downloaded as-is. A new setting has been added to disable this behaviour, but is currently not exposed
- Crashes that occurred when applying project validation corrections (for example if the base URL redirects, WebCopy will prompt to use the redirect version) were fatal
- Trying to save a CSV export with a relative filename crashed
- The quick scan diagram view could crash if invalid host names were detected
- The "Limit distance from base URL" setting now only applies to URLs that have a content type of text/html, e.g. it will prevent deep scanning whilst still allowing retrieval of all linked resources
- URLs that had exclusion rules would still get requested depending on the combination of project settings
- The CLI would crash if the recursive and output parameters were defined, and the specified output directory did not exist
- Client is no longer marked as dpi-aware, which should resolve pretty much all the problems with the application not displaying correctly on high DPI screens. This is an interim fix until dpi-awareness can be properly introduced.
- Fixed a crash that could occur when trying to query if the scan above root setting should be abled and an invalid URI was project
- Fixed a crash that could occur when the scan/download progress dialog was closed
- The Export CSV dialog wasn't localised correctly, resulting in seemingly two Cancel buttons
Removed:
- The PDF meta data provider has been removed
 OperaOpera 117.0 Build 5408.197 (64-bit)
OperaOpera 117.0 Build 5408.197 (64-bit) PC RepairPC Repair Tool 2025
PC RepairPC Repair Tool 2025 PhotoshopAdobe Photoshop CC 2025 26.5.0 (64-bit)
PhotoshopAdobe Photoshop CC 2025 26.5.0 (64-bit) OKXOKX - Buy Bitcoin or Ethereum
OKXOKX - Buy Bitcoin or Ethereum iTop VPNiTop VPN 6.4.0 - Fast, Safe & Secure
iTop VPNiTop VPN 6.4.0 - Fast, Safe & Secure Premiere ProAdobe Premiere Pro CC 2025 25.2.1
Premiere ProAdobe Premiere Pro CC 2025 25.2.1 BlueStacksBlueStacks 10.42.50.1004
BlueStacksBlueStacks 10.42.50.1004 Hero WarsHero Wars - Online Action Game
Hero WarsHero Wars - Online Action Game SemrushSemrush - Keyword Research Tool
SemrushSemrush - Keyword Research Tool LockWiperiMyFone LockWiper (Android) 5.7.2
LockWiperiMyFone LockWiper (Android) 5.7.2
Comments and User Reviews